Autoencoder
Autoencoder は、input を一度 low-dimensional な representation に圧縮し、そこから元の input を復元する neural network です。通常は、encoder と decoder という二つの部分から構成されます。
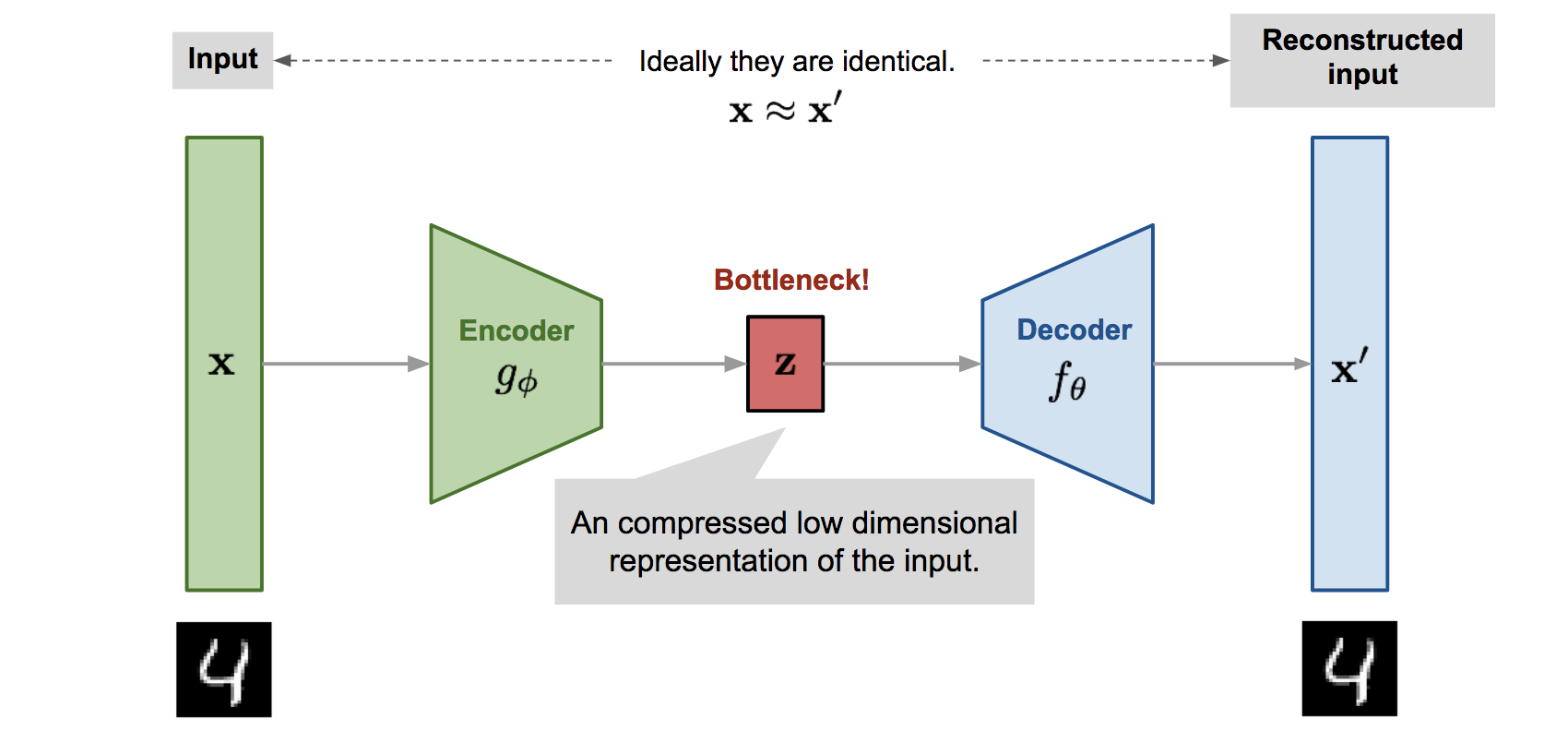
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。Encoder が input を latent representation に変換し、decoder が reconstruction を生成します。
構造
Autoencoder は、次の二つの関数として表せます。
ここで、 は encoder、 は decoder です。 は latent representation であり、 は reconstruction です。
目的
Autoencoder の目的は、input と reconstruction の差を小さくすることです。代表的には、次のような reconstruction loss を最小化します。
Autoencoder は、単に input をコピーするだけではなく、bottleneck を通じて data の重要な構造を latent representation に押し込めることを狙います。
Bottleneck の意味
Latent dimension が input dimension よりも小さい場合、network は input の情報をすべてそのまま通すことができません。そのため、reconstruction に必要な重要な factor を学習する必要があります。
この考え方は、Denoising Autoencoder、Sparse Autoencoder、Contractive Autoencoder、Variational Autoencoder へと発展していきます。
数式で見る autoencoder の圧縮と復元
Autoencoder は encoder と decoder からなります。入力 を latent に圧縮し、そこから復元 を作ります。
最も基本的な training objective は reconstruction loss です。
この式の気持ちは、「入力をそのまま覚えるのではなく、狭い latent bottleneck を通して必要な情報だけを残し、そこから元の入力を復元する」というものです。Latent dimension を小さくすると圧縮は強くなりますが、細部の復元は難しくなります。