ELBO
ELBO は Evidence Lower Bound の略であり、Variational Autoencoder の training objective として使われます。VAE では data likelihood を直接最大化したいのですが、posterior が扱いにくいため、代わりに ELBO を最大化します。
目的
VAE の latent variable model では、次のように data が生成されると仮定します。
本来最大化したいのは、次の marginal likelihood です。
しかし、この積分は一般に直接計算できません。そこで、近似 posterior を導入します。
ELBO の形
ELBO は次のように書けます。
この式は、二つの term から構成されます。
| Term | 役割 |
|---|---|
| Reconstruction term | Decoder が から を復元できるようにします。 |
| KL regularization term | を prior に近づけます。 |
なぜ lower bound なのか
ELBO は、次の関係を満たします。
KL Divergence は常に非負であるため、次が成り立ちます。
つまり、ELBO は log likelihood の lower bound です。
Forward KL と reversed KL
VAE では、近似 posterior と真の posterior の間の KL Divergence が重要です。KL Divergence は asymmetric であるため、どちらの向きで測るかによって振る舞いが変わります。
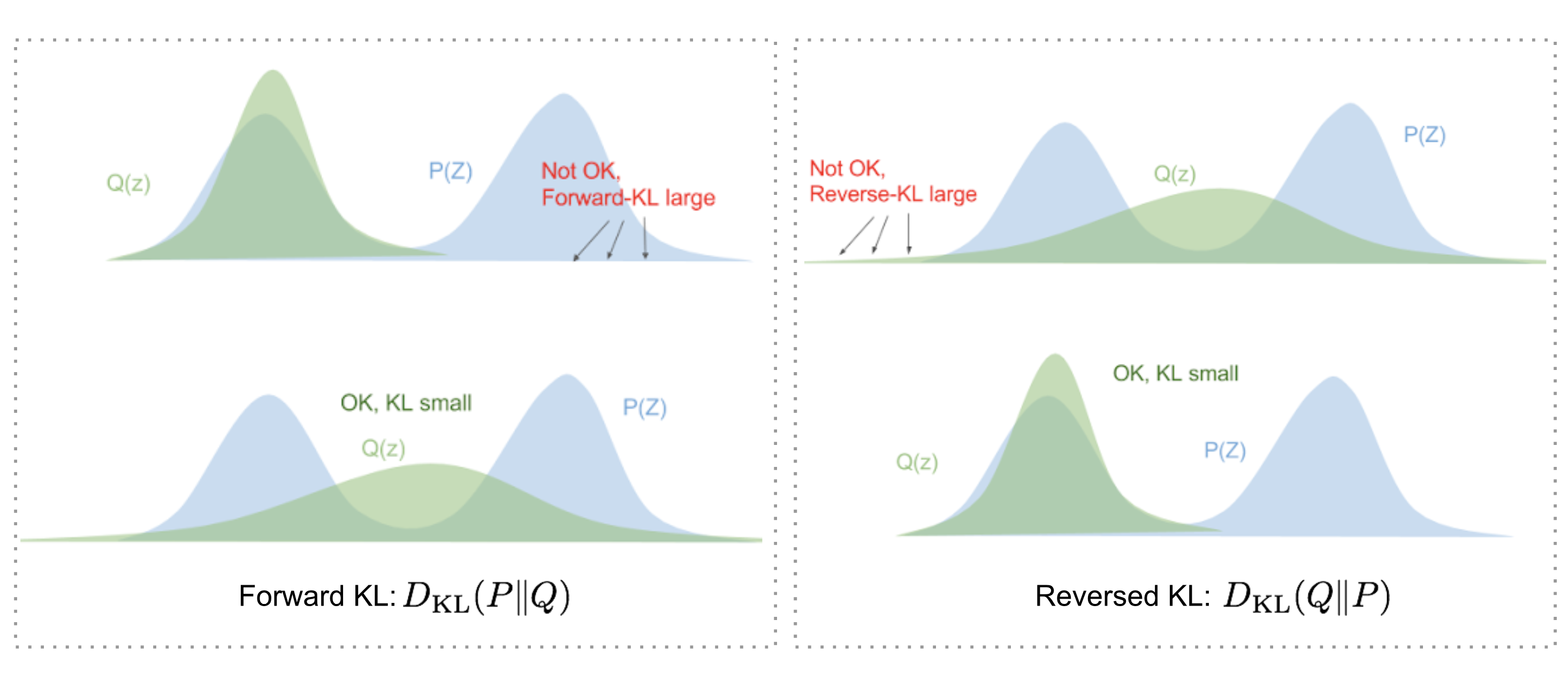
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。Forward KL と reversed KL は、multi-modal な distribution に対して異なる近似の振る舞いを示します。