Sparse Autoencoder
Sparse Autoencoder は、latent representation の多くの unit が inactive になるように制約を加えた Autoencoder です。Latent dimension が大きい場合でも、sparsity constraint によって meaningful な representation を学習しやすくします。
Sparsity constraint
Sparse Autoencoder では、hidden unit の平均 activation が小さくなるように penalty を加えます。目標 activation を 、実際の平均 activation を とすると、各 hidden unit に対する penalty は KL Divergence で表せます。
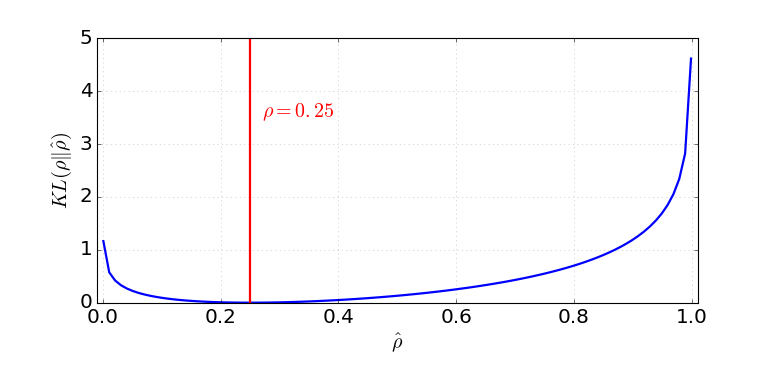
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。Target sparsity と実際の activation のずれを KL Divergence で penalize します。
k-sparse Autoencoder
k-sparse Autoencoder は、hidden layer の中で activation が大きい上位 個の unit だけを残し、それ以外を にする方法です。

画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。最も大きく activation した 個の hidden unit だけを残します。
直感
Sparse Autoencoder は、すべての unit を少しずつ使うのではなく、入力ごとに限られた unit だけを使うようにします。その結果、より disentangled で解釈しやすい representation が得られることがあります。
数式で見る sparsity penalty
Sparse Autoencoder は、latent activation が少数の unit だけを使うように regularization を入れます。
penalty は、多くの latent dimension を 0 に近づけます。この式の気持ちは、「入力を復元するために必要な少数の特徴だけを使い、解釈しやすい dictionary 的な表現を作る」というものです。
Activation の平均値を目標 sparsity に近づける KL penalty も使われます。
ここで、 は latent unit の平均 activation です。