Variational Autoencoder
Variational Autoencoder(以下 VAE)は、latent variable model と Autoencoder を組み合わせた generative model です。通常の Autoencoder が deterministic な latent representation を学習するのに対して、VAE は latent variable の probability distribution を学習します。
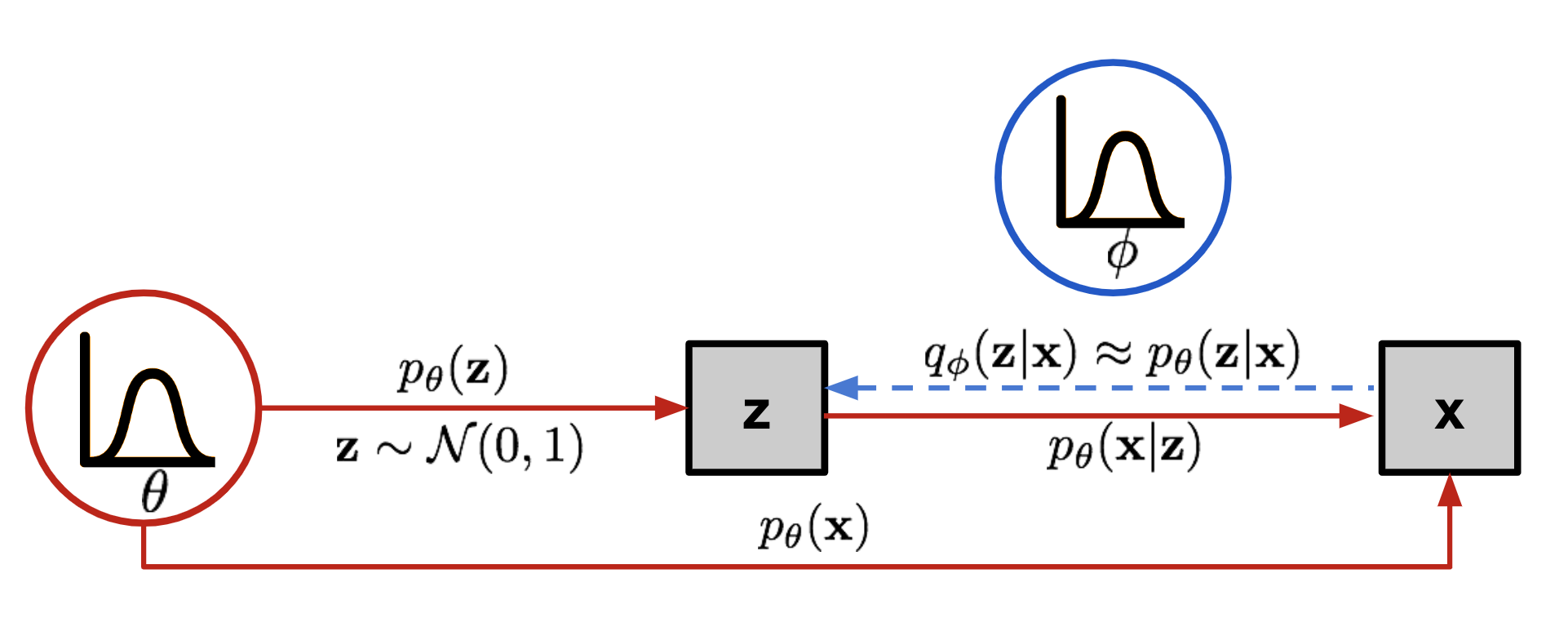
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。VAE では latent variable から data が生成されると仮定します。
Generative process
VAE では、data は latent variable から生成されると考えます。
ここで、 は prior distribution であり、多くの場合には standard Gaussian が使われます。
Decoder は、 を parameterize する neural network として解釈できます。
Inference problem
VAE では、本当は posterior を求めたいのですが、これは一般に直接計算できません。そこで、encoder によって近似 posterior を学習します。
Encoder は、input から latent distribution の parameter を出力します。Gaussian VAE では、平均 と分散 を出力します。
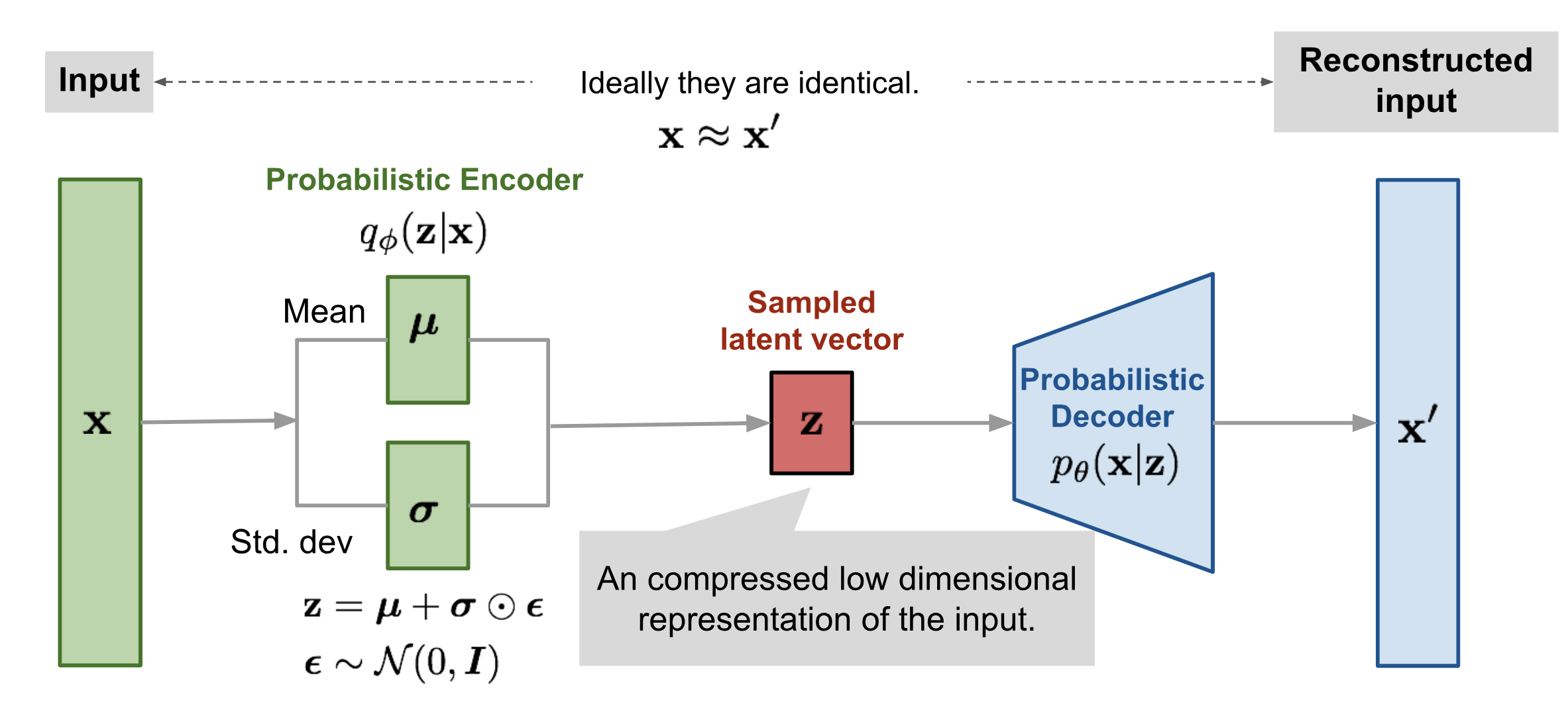
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。Encoder が と を出力し、そこから latent variable を sampling します。
VAE の training
VAE は、data likelihood を直接最大化する代わりに、ELBO を最大化します。ELBO は、reconstruction term と regularization term から構成されます。
第一項は、decoder が input をうまく復元できるようにします。第二項は、encoder が作る latent distribution を prior distribution に近づけます。
Reparameterization Trick
VAE では、 という sampling を含むため、そのままでは gradient を backpropagation しにくい問題があります。この問題を避けるために、Reparameterization Trick が使われます。
数式で見る VAE の ELBO
VAE は latent variable model として、 を仮定します。Posterior は直接計算しにくいため、encoder で近似します。
ELBO は次のように書けます。
第一項は reconstruction likelihood で、latent から入力を説明できるようにします。第二項は posterior が prior から離れすぎないようにする regularization です。
この式の気持ちは、「入力をよく復元したいが、latent space をばらばらにしすぎると sampling できなくなるので、Gaussian prior に近い滑らかな latent space を保つ」というものです。