VQ-VAE
VQ-VAE、つまり Vector Quantized Variational Autoencoder は、continuous な latent variable ではなく、discrete な latent representation を使う VAE 系の model です。
基本 idea
通常の VAE では、latent variable は Gaussian distribution などの continuous distribution から sampling されます。一方で、VQ-VAE では、encoder の出力を codebook に含まれる embedding vector のうち最も近いものへ quantize します。
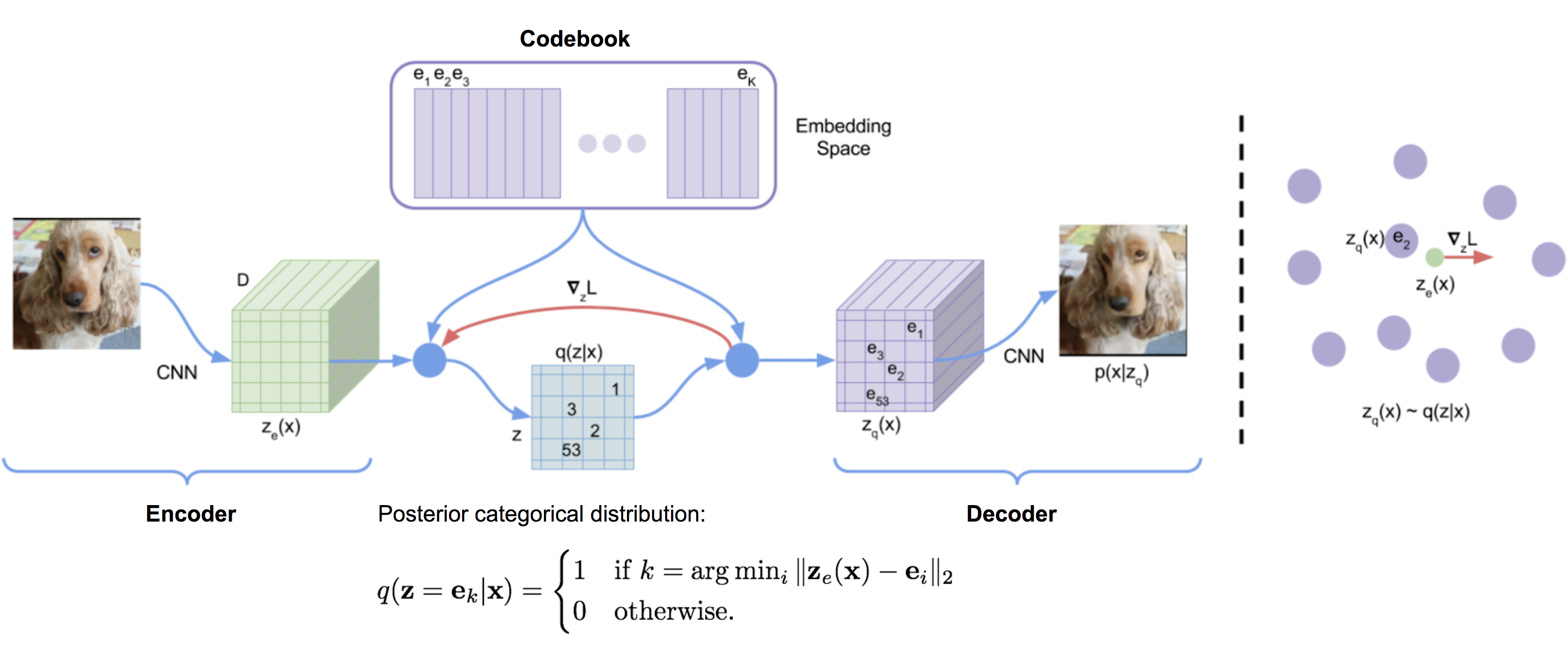
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。Encoder の出力を codebook の embedding に割り当て、decoder がそこから reconstruction を生成します。
Codebook
VQ-VAE では、codebook を持ちます。Encoder の出力 に最も近い embedding を選び、quantized latent として使います。
この discrete latent representation によって、画像、音声、言語のような discrete structure を持つ data を扱いやすくなります。
VQ-VAE-2
VQ-VAE-2 は、VQ-VAE を hierarchical に拡張した model です。Top-level latent は global な structure を捉え、bottom-level latent は local な detail を捉えます。
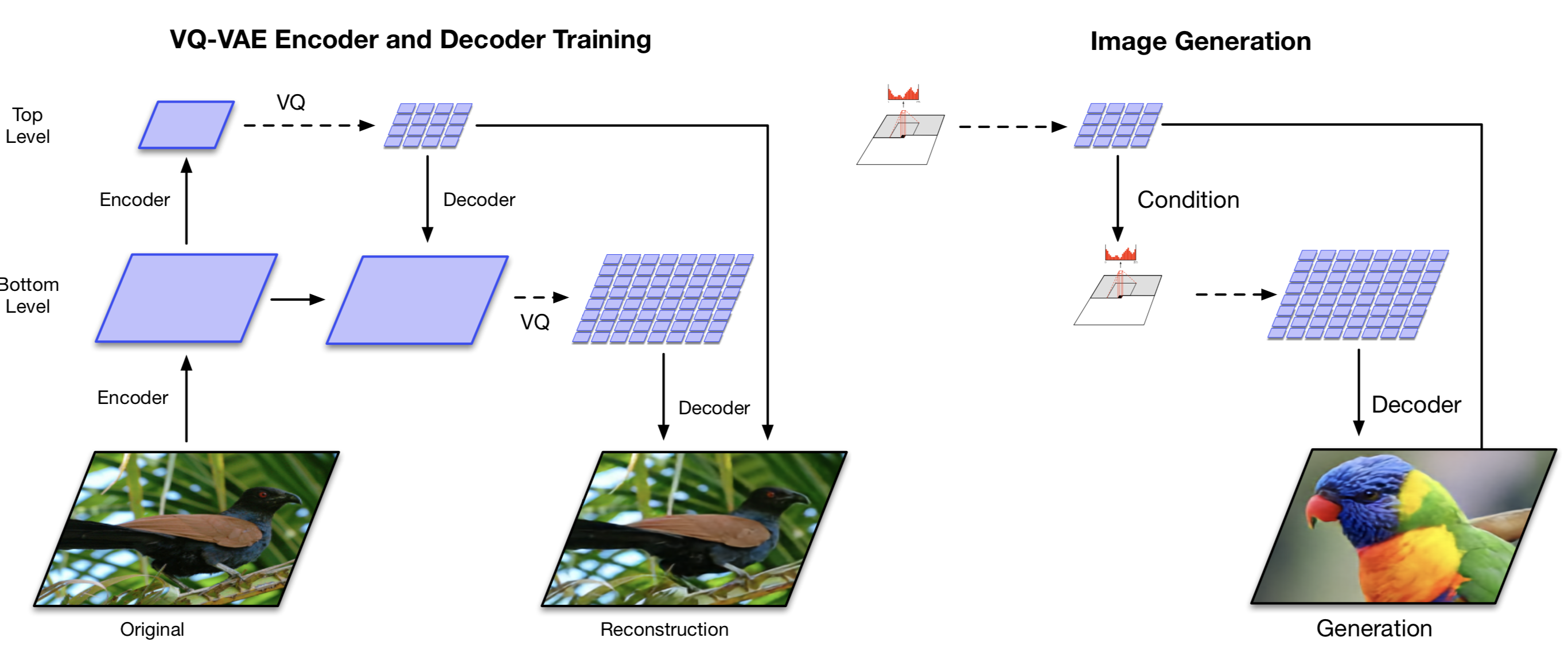
画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。VQ-VAE-2 は複数 level の discrete latent variable を使います。

画像出典: Lilian Weng, “From Autoencoder to Beta-VAE”。VQ-VAE-2 の training と sampling の流れが示されています。
数式で見る VQ-VAE の codebook quantization
VQ-VAE では、encoder 出力 を連続値のまま使わず、codebook の最近傍 vector に置き換えます。
Decoder は quantized latent から入力を復元します。
Training loss は、reconstruction、codebook、commitment の三つに分かれます。
この式の気持ちは、「encoder は codebook のどれかに近い表現を出し、codebook は encoder 出力に追随し、decoder は離散 latent から復元する」というものです。離散 token 化された latent は、autoregressive model や transformer と組み合わせやすくなります。