Cascaded Diffusion and unCLIP
High-resolution image generation では、一度に大きな画像を生成するのではなく、低解像度から高解像度へ段階的に生成する方法が使われます。Cascaded Diffusion と unCLIP は、その代表的な approach です。
Cascaded Diffusion
Cascaded Diffusion では、まず低解像度の画像を生成し、その後に super-resolution diffusion model を使って段階的に解像度を上げます。
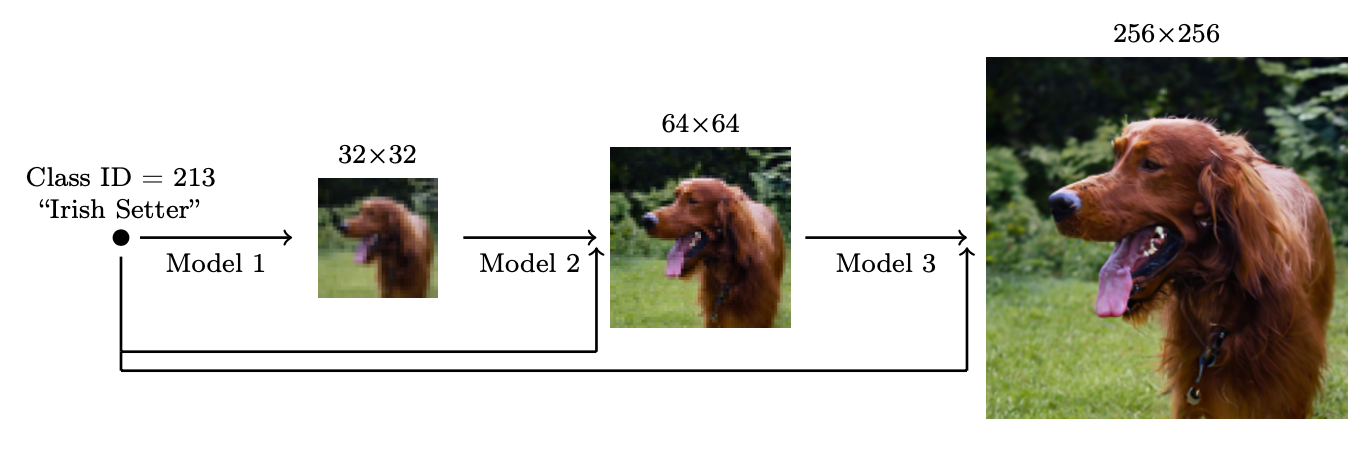
画像出典: Lilian Weng, “What are Diffusion Models?”。複数の diffusion model を cascade して、低解像度から高解像度へ生成します。
unCLIP
unCLIP は、CLIP embedding を介して image generation を行う approach です。Text prompt から CLIP text embedding を得て、それに対応する image embedding を生成し、そこから diffusion decoder によって画像を生成します。
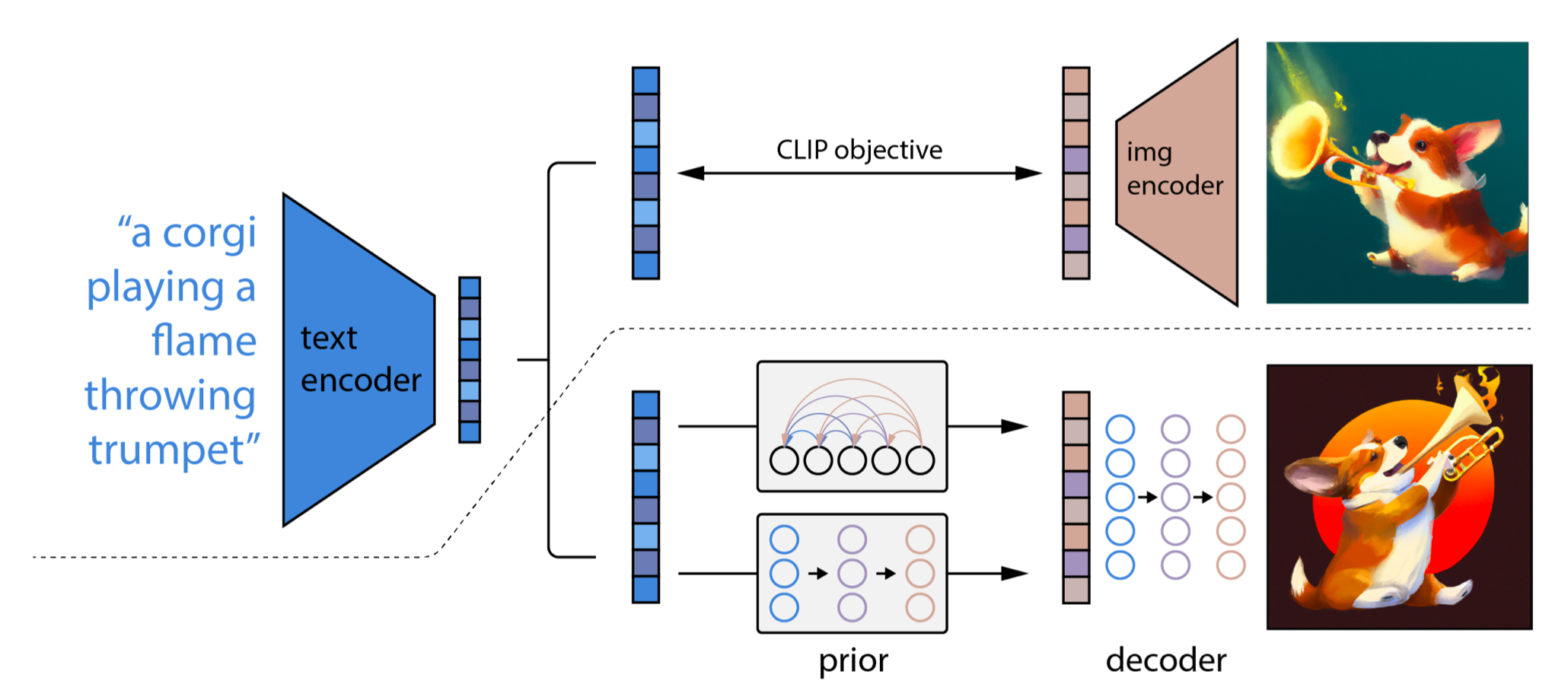
画像出典: Lilian Weng, “What are Diffusion Models?”。CLIP latent space を介して text-to-image generation を行う構成です。
なぜ段階的生成が有効なのか
高解像度画像は dimension が大きく、直接 modeling するのが難しいため、段階的に生成することで各 model の task を簡単にできます。低解像度 model は global structure を担当し、super-resolution model は local detail を補います。
数式で見る cascaded generation
Cascaded diffusion は、低解像度画像を生成してから、super-resolution model で段階的に高解像度化します。
この式の気持ちは、「いきなり高解像度を生成するのではなく、まず構図や内容を低解像度で決め、その後に detail を追加する」というものです。
unCLIP 系では、text から CLIP image embedding を予測し、その embedding を条件に diffusion decoder が画像を生成します。
ここで、 は image embedding、 は text prompt です。この分解により、semantic な構図と pixel-level detail を分けて扱えます。