Diffusion Model Architectures
Diffusion Model の性能は、denoising network の architecture に大きく依存します。代表的な architecture には、U-Net、ControlNet、Diffusion Transformer(DiT)があります。
U-Net
U-Net は、Diffusion Model で広く使われる architecture です。Encoder-decoder 構造と skip connection によって、global context と local detail の両方を扱えます。
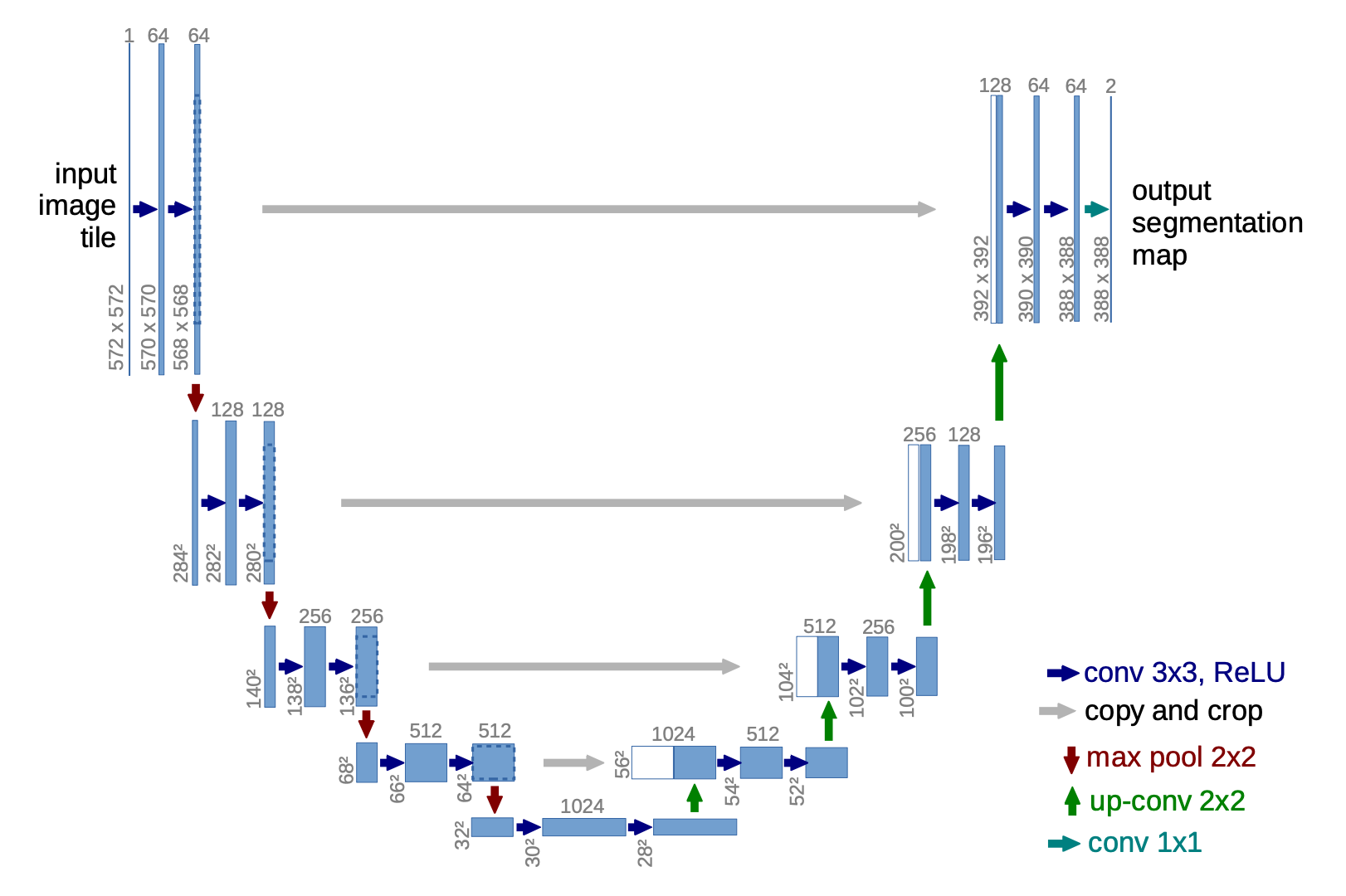
画像出典: Lilian Weng, “What are Diffusion Models?”。Diffusion Model で使われる U-Net architecture の例です。
ControlNet
ControlNet は、既存の diffusion model に追加の condition を与えて、生成結果を細かく制御するための architecture です。Edge map、pose、depth map などを condition として使えます。
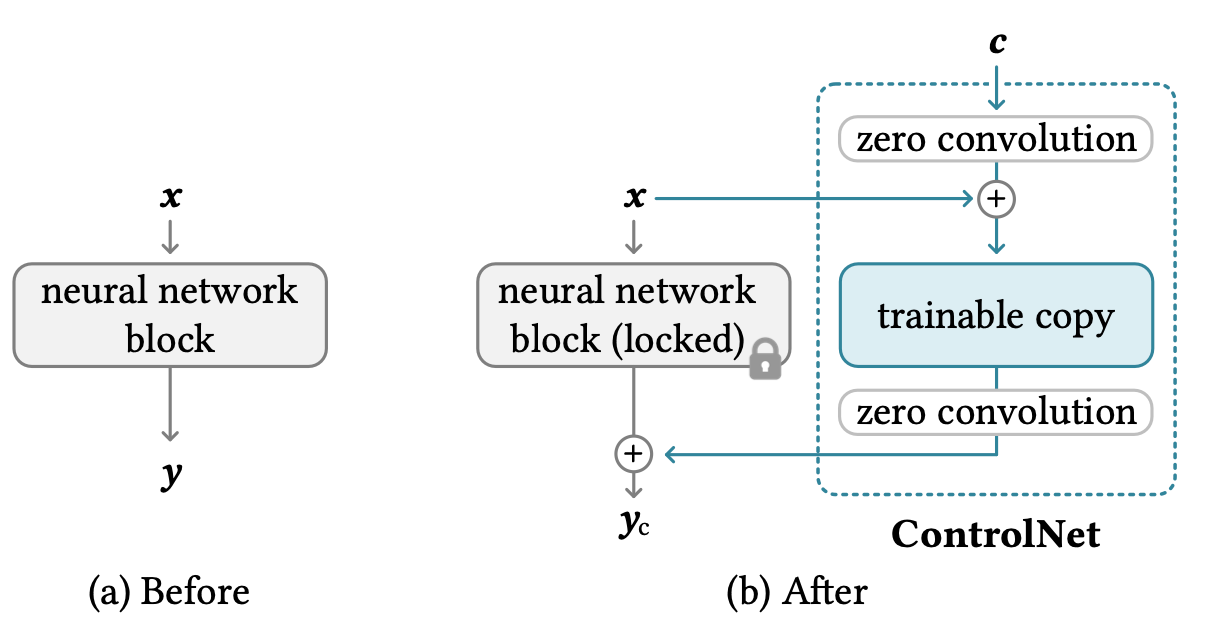
画像出典: Lilian Weng, “What are Diffusion Models?”。Pretrained diffusion model に condition branch を追加する構成です。
Diffusion Transformer
Diffusion Transformer(DiT)は、U-Net の代わりに Transformer architecture を使う diffusion model です。Vision Transformer のような patch-based representation を使い、大規模 training と相性がよい構成です。
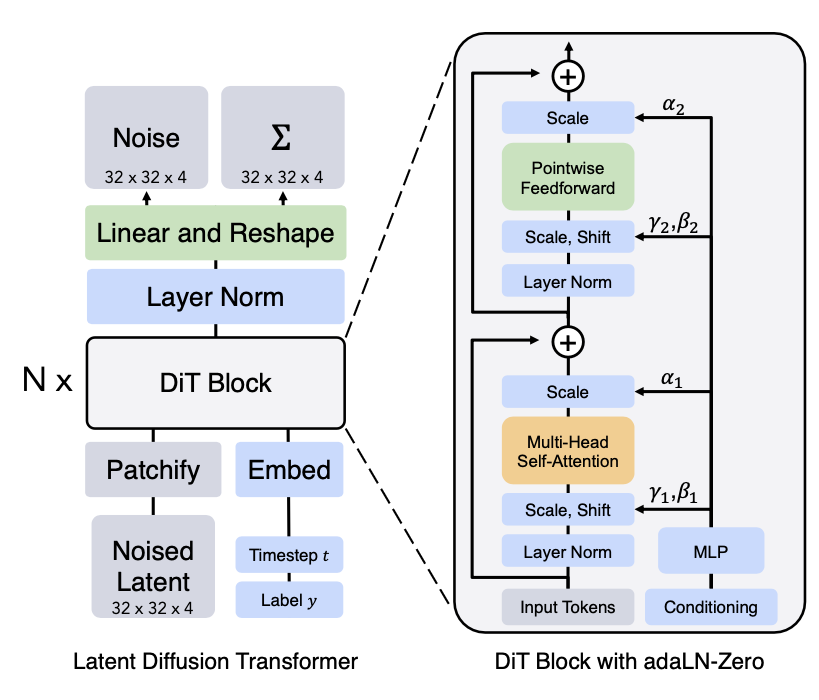
画像出典: Lilian Weng, “What are Diffusion Models?”。Diffusion Transformer の architecture が示されています。
数式で見る U-Net / DiT の denoising function
Diffusion architecture は、noisy sample 、timestep 、condition から noise または clean sample を予測する関数として書けます。
U-Net は、downsample / bottleneck / upsample と skip connection で multi-scale feature を扱います。Skip connection は概念的に次のように書けます。
この式の気持ちは、「低解像度の global context と、高解像度の local detail を復元時に結合する」というものです。
DiT は、latent patch token に transformer block を適用します。
ここで、 は timestep embedding、 は condition embedding です。DiT は scaling しやすい一方で、token 数が増えると attention cost が大きくなります。