Latent Diffusion
Latent Diffusion は、pixel space ではなく、autoencoder によって圧縮された latent space の中で diffusion process を行う方法です。Stable Diffusion のような text-to-image model の基礎として重要です。
Motivation
High-resolution image を pixel space で直接生成すると、計算コストが非常に大きくなります。Latent Diffusion では、まず画像を encoder で low-dimensional latent representation に圧縮します。そして、その latent space 上で diffusion model を training します。
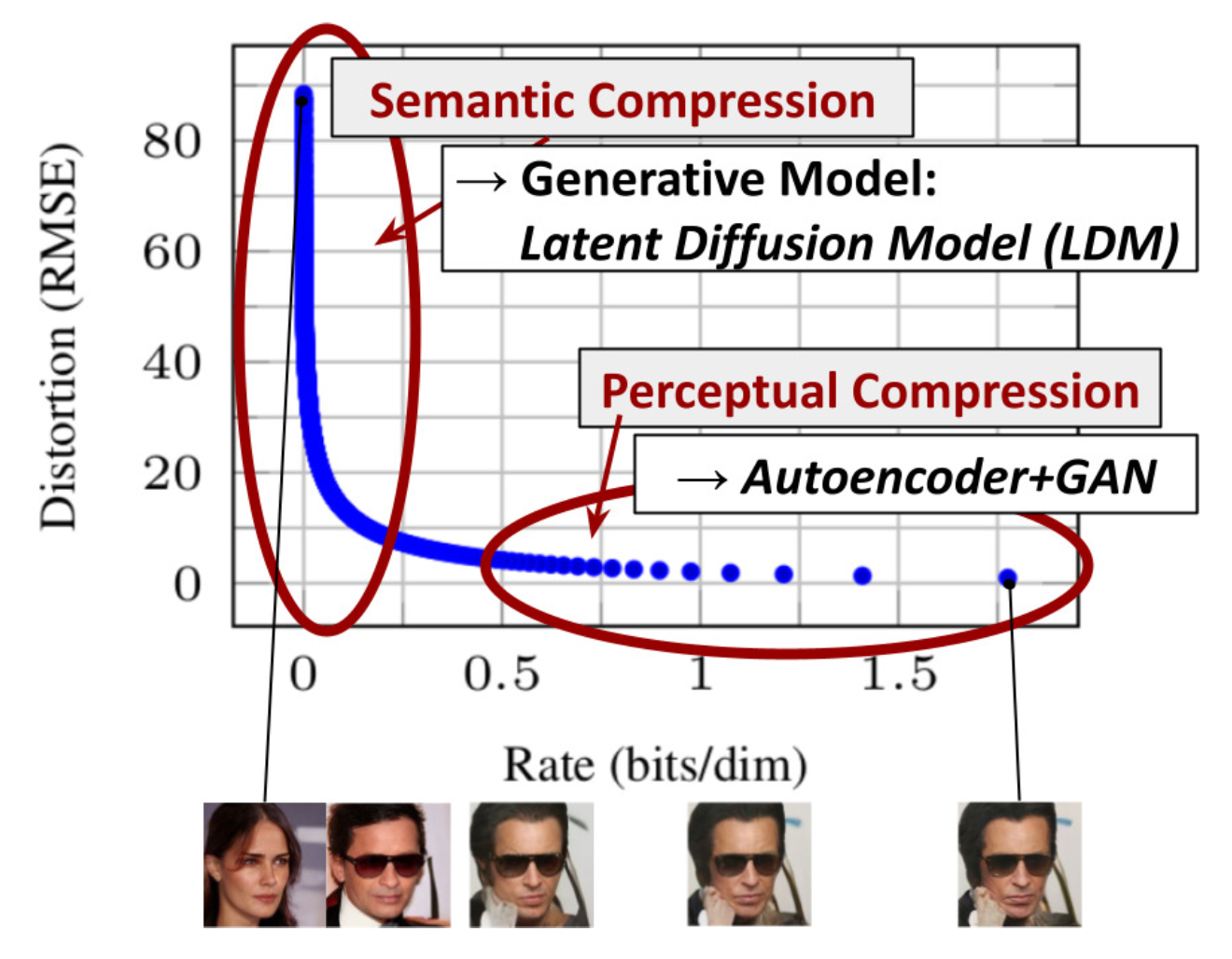
画像出典: Lilian Weng, “What are Diffusion Models?”。Compression rate と reconstruction quality の関係が示されています。
Architecture
Latent Diffusion の典型的な構成は、次の三つです。
- Autoencoder によって image を latent に圧縮します。
- Latent space で diffusion model を training します。
- Generated latent を decoder に通して image に戻します。
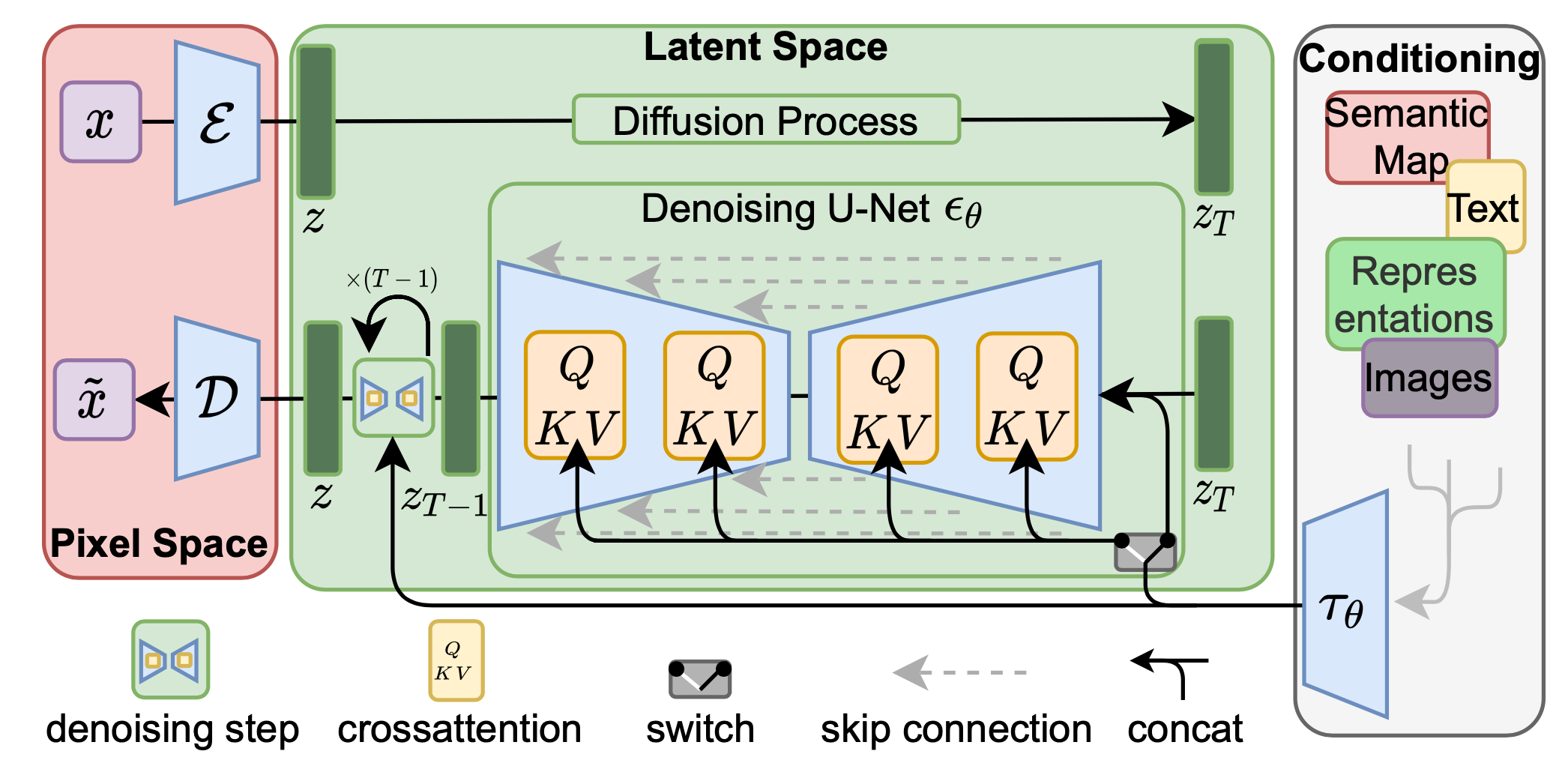
画像出典: Lilian Weng, “What are Diffusion Models?”。Image を latent space に圧縮し、その空間で diffusion を行う構成です。
利点
Latent Diffusion には、次の利点があります。
- Pixel space よりも低次元なので、計算コストが下がります。
- High-resolution image generation を扱いやすくなります。
- Text condition などの condition を組み合わせやすくなります。
数式で見る latent space での diffusion
Latent Diffusion は、pixel 空間ではなく autoencoder の latent 空間で diffusion を行います。Encoder を 、decoder を とすると、画像 は latent に圧縮されます。
Diffusion model は、この に対して noise prediction loss を最小化します。
ここで、 は text embedding などの condition です。この式の気持ちは、「高解像度 pixel を直接 denoise する代わりに、意味を保った低次元 latent を denoise することで計算量を下げる」というものです。Decoder は、denoise された latent を最終的な画像へ戻す役割を持ちます。