Speeding up Diffusion Models
Diffusion Model の大きな課題は、sampling に多くの denoising step が必要なことです。Original DDPM では数百から数千 step が必要になることがあり、GAN や VAE と比べて sampling が遅くなりやすいです。
Fewer sampling steps
Sampling step を減らす方法として、DDIM などの deterministic または non-Markovian な sampling method が提案されています。これにより、少ない step でも比較的高品質な sample を生成できます。
画像出典: Lilian Weng, “What are Diffusion Models?”。Sampling step 数を減らした場合の生成結果が比較されています。
Progressive Distillation
Progressive Distillation は、多くの step を使う teacher model から、より少ない step で sampling できる student model を学習する方法です。
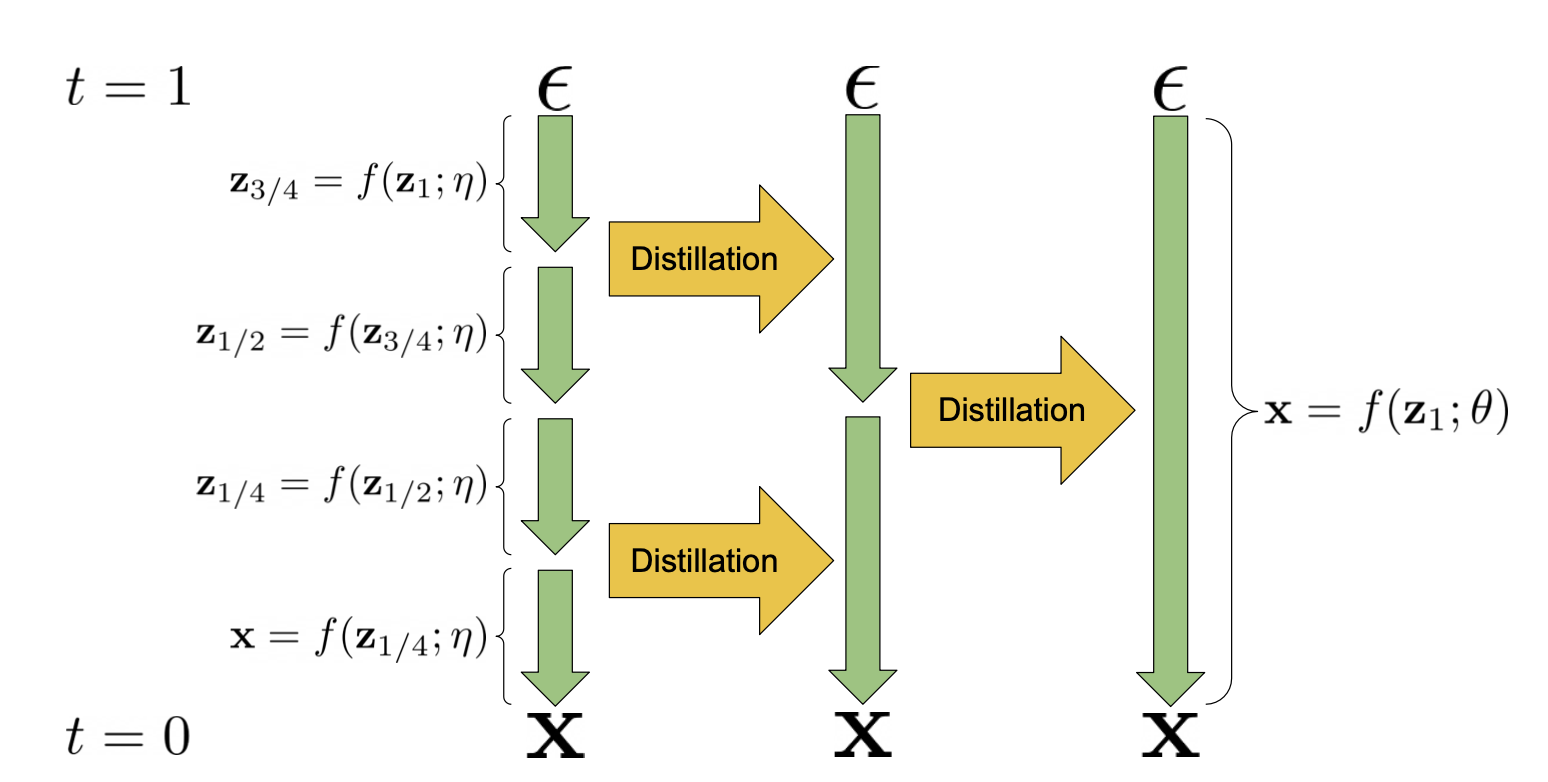
画像出典: Lilian Weng, “What are Diffusion Models?”。Teacher の複数 step を student の少ない step に蒸留します。

画像出典: Lilian Weng, “What are Diffusion Models?”。Progressive Distillation の algorithm が示されています。
Consistency Models
Consistency Models は、同じ diffusion trajectory 上の異なる noise level から、同じ clean sample へ写すように学習する方法です。これにより、one-step または few-step generation を狙います。

画像出典: Lilian Weng, “What are Diffusion Models?”。異なる時刻の sample が同じ clean sample に対応するように学習します。
画像出典: Lilian Weng, “What are Diffusion Models?”。Consistency Models の生成結果例です。
数式で見る step 数削減と distillation
Diffusion sampling は、通常 step の denoising chain をたどります。
高速化の基本は、この chain を少ない step で近似することです。
Distillation では、多 step teacher の出力を少 step student が真似します。
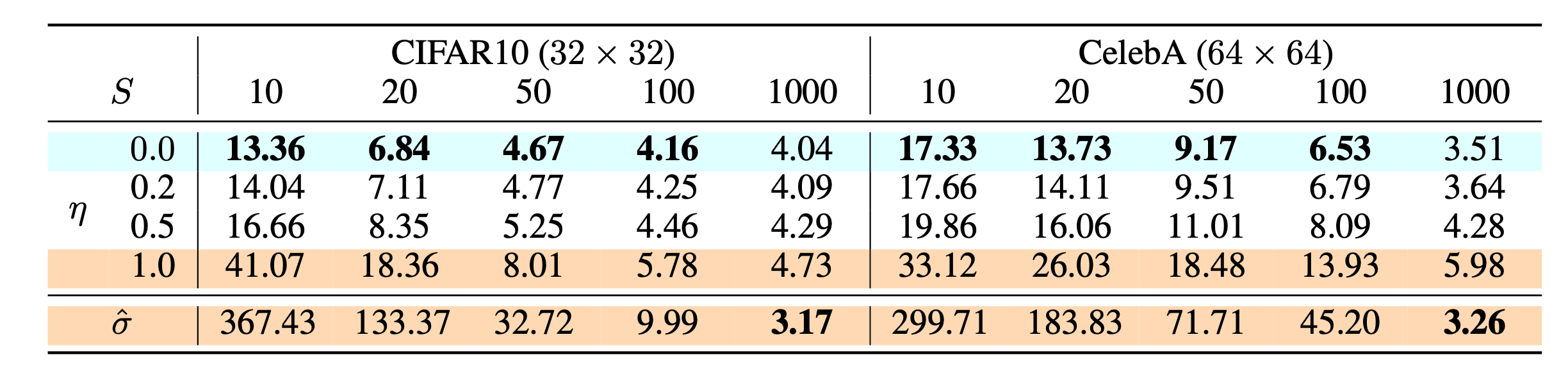
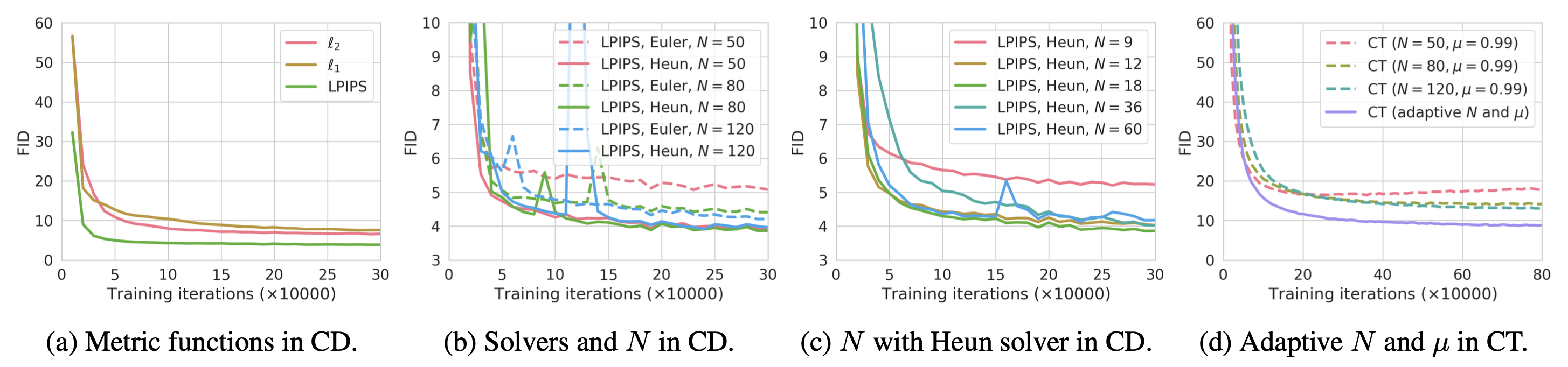
この式の気持ちは、「teacher が何 step もかけて行う denoising を、student が少ない step で近似できるように学習する」というものです。高速化では、品質、diversity、prompt fidelity、計算量の trade-off を見る必要があります。