PixelRNN, PixelCNN, and WaveNet
PixelRNN、PixelCNN、WaveNet は、autoregressive factorization を画像や音声に適用した代表的な model です。
PixelRNN
PixelRNN は、画像の pixel を順番に生成します。ある pixel の値は、それ以前に生成された pixel に条件づけられます。
![]()
画像出典: Lilian Weng, “Flow-based Deep Generative Models”。PixelRNN では、現在の pixel が過去の context に条件づけられます。
Diagonal BiLSTM を使うことで、画像上の広い context を取り込むことができます。
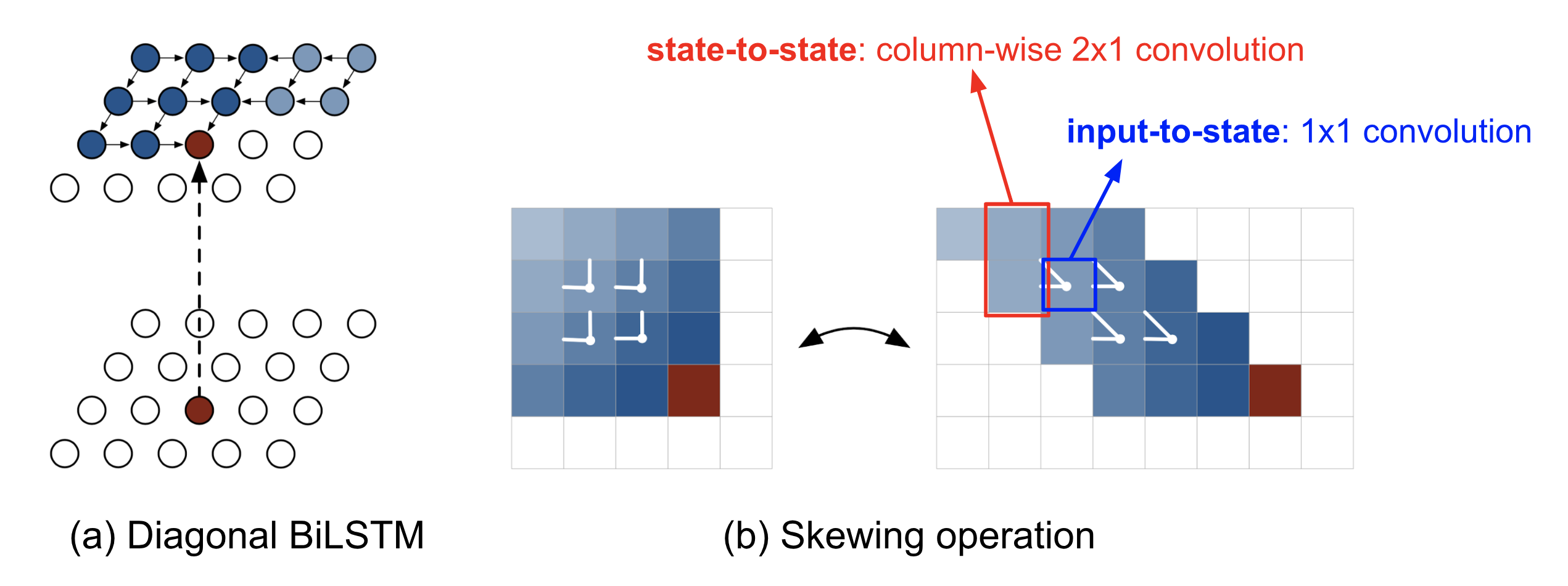
画像出典: Lilian Weng, “Flow-based Deep Generative Models”。Diagonal BiLSTM によって画像の依存関係を modeling します。
PixelCNN
PixelCNN は、masked convolution によって autoregressive な依存関係を実現します。
![]()
画像出典: Lilian Weng, “Flow-based Deep Generative Models”。Mask によって、未来の pixel を見ないように convolution を制限します。
WaveNet
WaveNet は、音声波形を autoregressive に生成する model です。Dilated convolution を使うことで、長い temporal context を効率的に取り込みます。
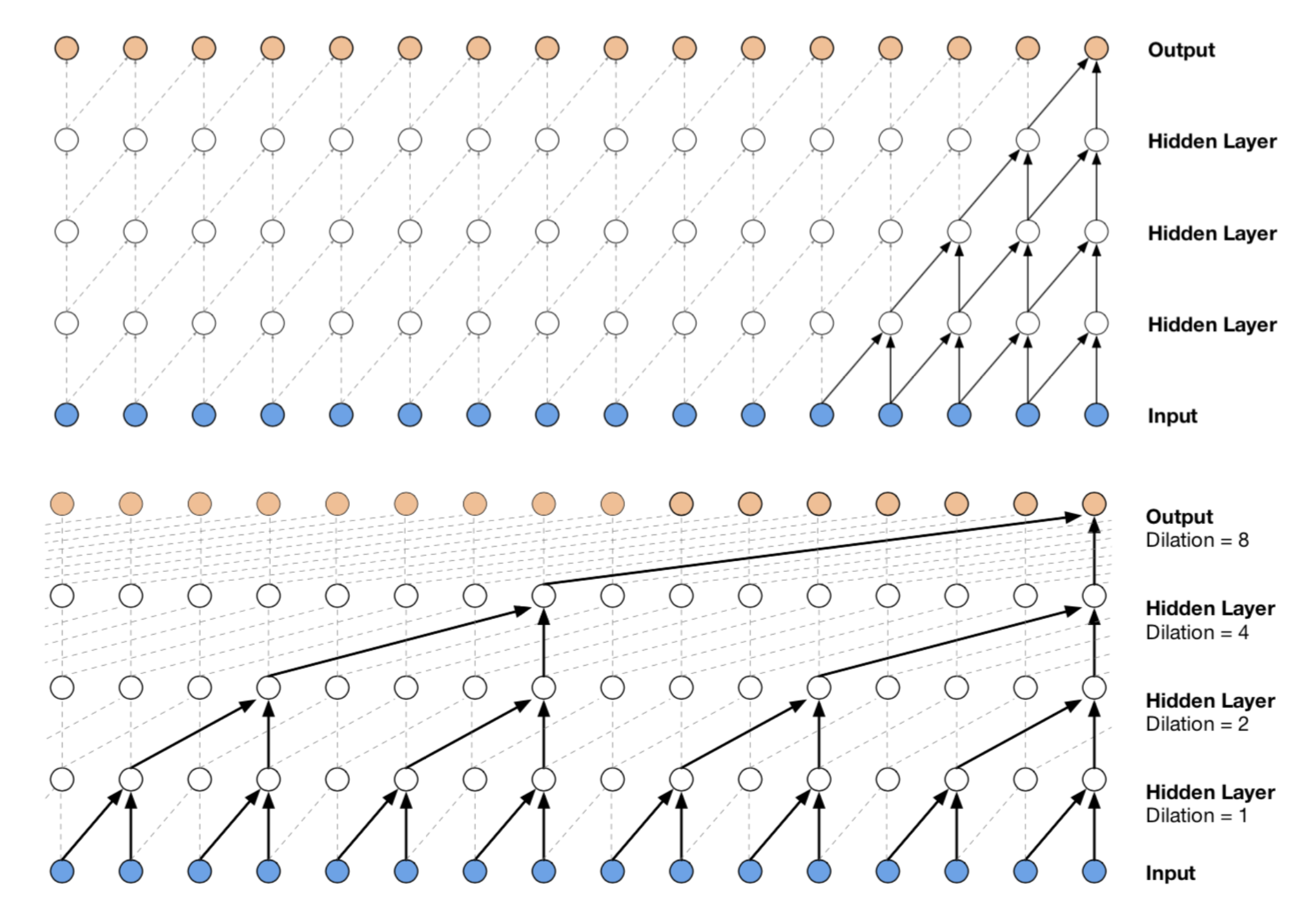
画像出典: Lilian Weng, “Flow-based Deep Generative Models”。WaveNet は dilated causal convolution を使って音声を modeling します。
数式で見る autoregressive factorization
PixelRNN、PixelCNN、WaveNet は、data の joint distribution を順序付きの conditional distribution に分解します。画像 の pixel を順序付けると、次のように書けます。
音声 waveform でも同様です。
この式の気持ちは、「一度に全体を生成するのではなく、過去に生成した部分を条件に次の pixel / sample を一つずつ生成する」というものです。
Masked convolution は、未来の pixel を見ないようにするための構造です。
これにより exact likelihood を計算できる一方、sampling は逐次的になりやすく、生成速度が遅いという欠点があります。