Generative Adversarial Network
Generative Adversarial Network(以下 GAN)は、Generator と Discriminator という二つの model を競わせながら training する generative model です。画像、自然言語、音楽のような現実世界の豊かな content を生成するために使われます。
基本構造
GAN は、次の二つの model から構成されます。
| Model | 役割 |
|---|---|
| Generator | noise variable を受け取り、synthetic sample を生成します。 |
| Discriminator | 与えられた sample が real dataset から来たものか、Generator が作った fake sample なのかを判定します。 |
Generator は、Discriminator をだませるほど本物らしい sample を作ろうとします。Discriminator は、real sample と fake sample を正しく見分けようとします。この二つの model の競争によって、Generator は real data distribution に近い sample を生成する方向へ更新されます。
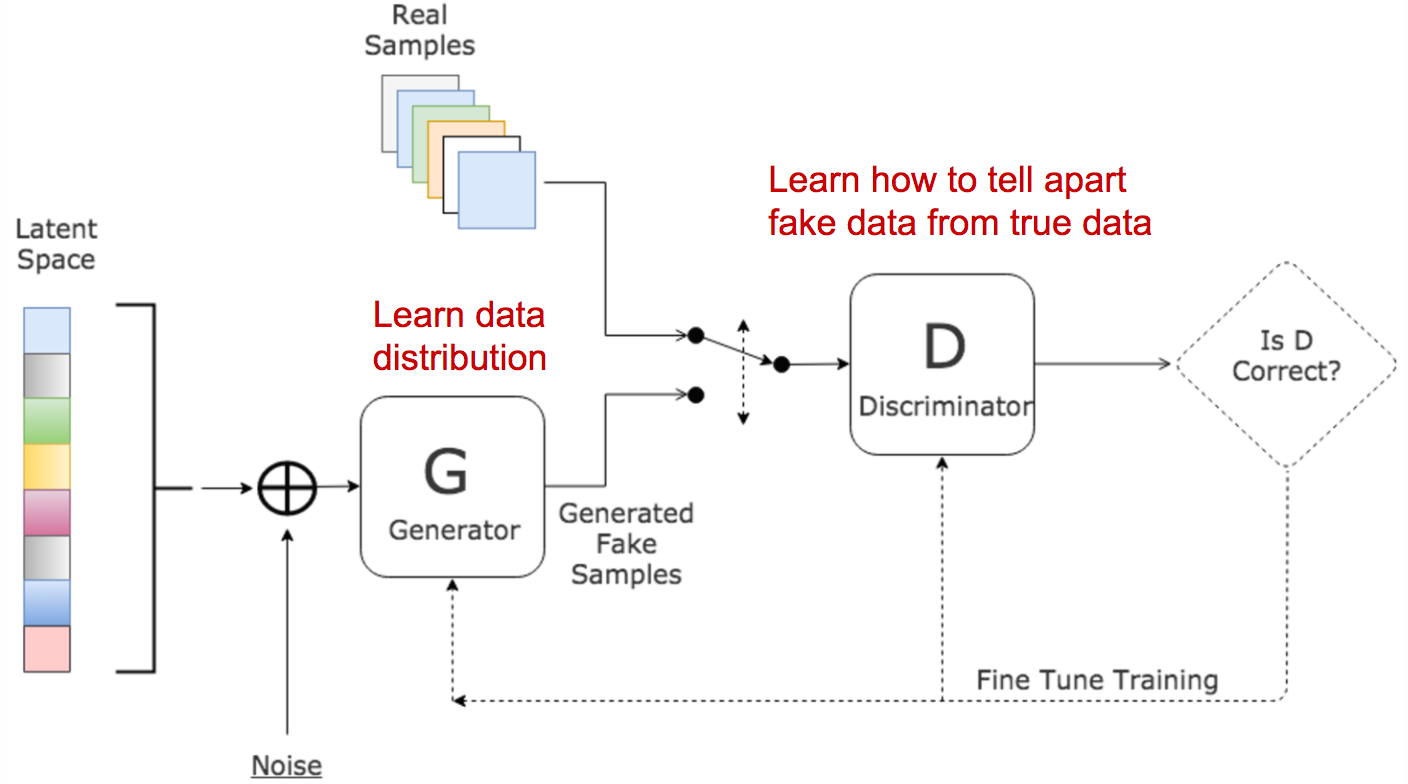
画像出典: Lilian Weng, “From GAN to WGAN”。Generator が noise から fake sample を作り、Discriminator が real sample と fake sample を見分ける構造が示されています。
記号
| Symbol | 意味 |
|---|---|
| noise input の distribution です。多くの場合には uniform distribution が使われます。 | |
| Generator が作る data の distribution です。 | |
| real sample の data distribution です。 |
Minimax objective
Discriminator は、real sample に対して高い確率を出し、fake sample に対して低い確率を出すように training されます。一方で、Generator は、fake sample に対して Discriminator が高い確率を出すように training されます。
この関係は、次の minimax game として書けます。
Generator が作った distribution を使うと、次のようにも書けます。
第一項は、Discriminator が real sample を正しく real と判断することを促します。第二項は、Discriminator が fake sample を正しく fake と判断することを促します。Generator は、この第二項を小さくする方向に更新されます。
Optimal Discriminator
Generator を固定したとき、Discriminator にとって最適な出力は次の形になります。
ある が real distribution の中でよく現れ、generated distribution の中ではあまり現れない場合、 は に近づきます。反対に、ある が generated distribution の中でよく現れ、real distribution の中ではあまり現れない場合、 は に近づきます。
Generator が十分に良くなり、 が成り立つと、Discriminator は real sample と fake sample を区別できなくなります。このとき、すべての について になります。
Global optimum
であり、 であるとき、GAN は global optimum に到達しています。このとき、loss は次の値になります。
この状態では、Generator は real data distribution を再現しており、Discriminator は coin flip と同程度の判断しかできません。
Loss と JS Divergence の関係
Discriminator が optimal であるとき、GAN の loss は Jensen-Shannon Divergence と次のように関係します。
つまり、vanilla GAN は、 を に近づけるように JS Divergence を小さくしていると解釈できます。ただし、real distribution と generated distribution の support が重ならない場合には、この見方が training の難しさにつながります。