Vanishing Gradient in GAN
Vanishing gradient は、GAN training の代表的な失敗要因の一つです。Discriminator が強くなりすぎると、Generator が学習に使える gradient がほとんど得られなくなります。
Discriminator が完璧な場合
Discriminator が完璧に近づくと、real sample に対しては となり、generated sample に対しては となります。
この状況では、Generator が受け取る学習信号が非常に弱くなります。結果として、Generator の update がほとんど進まなくなります。
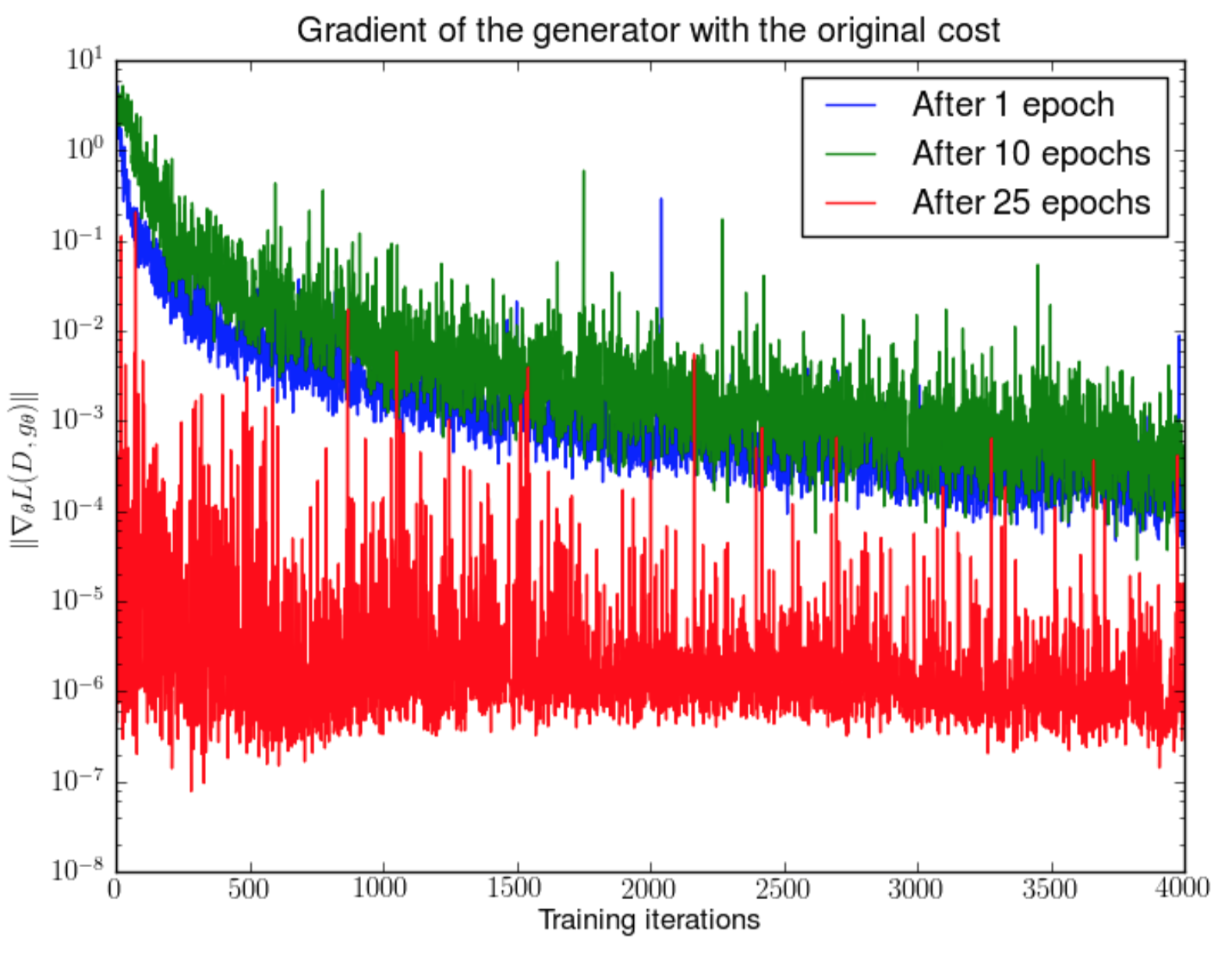
画像出典: Lilian Weng, “From GAN to WGAN”。Generator を固定したうえで Discriminator を training すると、gradient norm が急速に減少することが示されています。
GAN の dilemma
GAN training には、次のような dilemma があります。
- Discriminator が弱い場合には、Generator は正確な feedback を受け取れません。
- Discriminator が強すぎる場合には、Generator が受け取る gradient が に近づき、学習が非常に遅くなるか止まってしまいます。
この dilemma は、GAN の training を難しくする中心的な要因です。
JS Divergence との関係
Vanilla GAN の loss は、optimal Discriminator のもとでは Jensen-Shannon Divergence と関係します。しかし、real distribution と generated distribution の support が disjoint であると、JS Divergence は滑らかな gradient を与えにくくなります。
この問題に対する一つの解決策が、Wasserstein Distance を loss として使う Wasserstein GAN です。
数式で見る gradient vanishing
Vanilla GAN の minimax generator loss は次の通りです。
Discriminator が非常に強いと、fake sample に対して になります。このとき、generator は「fake である」と完全に見抜かれており、分布の support が real data と重ならない場合、JS divergence はほぼ定数になり、generator に有用な gradient が届きにくくなります。
Non-saturating loss は次のように書けます。
この式の気持ちは、「Discriminator をだます方向、つまり を直接大きくする方向に generator を更新する」というものです。WGAN が Wasserstein distance を使うのも、support が離れている状態でも意味のある gradient を得るためです。