3D U-Net and DiT for Video
Video Diffusion Models で使われる denoising network の architecture は、画像生成と同じく、大きく分けて U-Net 系と Transformer 系に分類できます。Video では時間軸が加わるため、空間方向と時間方向の両方を扱える構造が必要になります。
3D U-Net
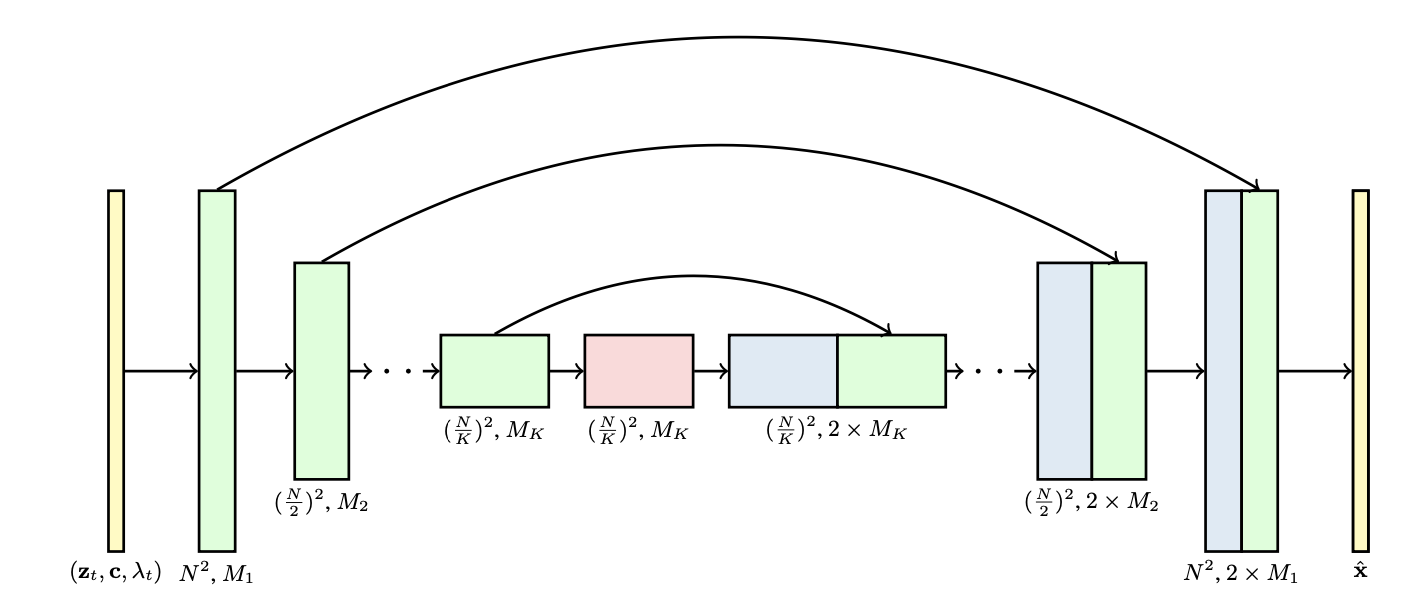
3D U-Net は、空間方向に加えて時間方向にも convolution を適用する U-Net です。Video Diffusion Models では、image 用の 2D U-Net を時間軸へ拡張した構造が広く使われます。
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。3D U-Net は空間方向と時間方向の両方で encoder-decoder 構造を持ちます。
実用上は、計算コストを抑えるために、純粋な 3D convolution ではなく、spatial convolution と temporal convolution を分離した「factorized space-time convolution」がよく使われます。Attention についても同様に、spatial attention と temporal attention に分離する構成が一般的です。
Diffusion Transformer for Video
Diffusion Transformer(DiT)は、U-Net の代わりに Transformer を使う diffusion model です。Video では、image latent code を spacetime の patch 列として扱い、Transformer の input token として渡します。

画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Sora は spacetime patch を token として扱う diffusion transformer です。
DiT 系の architecture は scaling との相性がよく、大規模 dataset と大きな model size との組み合わせで強い性能を示します。Sora はこの方向の代表例です。
選び方
- 3D U-Net 系: Pre-trained image U-Net を inflate して video へ拡張しやすく、Make-A-Video、Video LDM、Lumiere などで採用されています。
- DiT 系: Spacetime patch 単位で扱うため、長い video や高解像度への scaling に向きます。Sora が代表例です。
数式で見る temporal attention
Video transformer では、video latent を空間 token と時間 token の列として扱います。Frame 、patch の token を とすると、temporal attention は同じ spatial location または全 token にわたって時間方向の依存を集約します。
時間方向だけに attention する場合、query は同じ の過去・未来 frame token を参照します。この式の気持ちは、「各 frame を独立に denoise するのではなく、同じ物体が時間方向にどう動くかを参照しながら denoise する」というものです。
3D U-Net は convolution kernel を時間方向にも拡張します。
これは、局所的な時空間近傍から motion cue を取り込む操作です。