ControlVideo
ControlVideo(Zhang ら, 2023)は、text prompt と motion sequence(depth map や edge map など) を条件として video を生成する training-free な手法です。ControlNet をベースとし、video 向けに三つの仕組みを追加します。
Cross-frame attention
ControlVideo の cross-frame attention では、self-attention module の中で全 frame 間の完全な相互作用を導入します。各時刻の latent frame をすべて matrix に写すことで、frame 間のあらゆる相互参照を可能にします。
Text2Video-Zero は、すべての frame が最初の frame のみを attend する設計でしたが、ControlVideo はそれを「全 frame 同士の attention」へ拡張する点が異なります。
Interleaved-frame smoother
Interleaved-frame smoother は、ちらつきを抑えるための仕組みです。各 time step で、偶数 frame または奇数 frame を交互に対象として frame interpolation を行い、対応する三 frame の clip を smoothing します。Smoothing の結果として、frame 数は時間とともに減少していきます。
Hierarchical sampler
Hierarchical sampler は、memory 制約のもとで長い video の時間的整合性を確保するための仕組みです。長い video を複数の短い clip に分割し、各 clip の代表となる key frame を選びます。Model は、まずすべての key frame を full cross-frame attention によって事前生成し、長距離の一貫性を確保します。その後、各短い clip は、対応する key frame に条件づけて順番に生成されます。
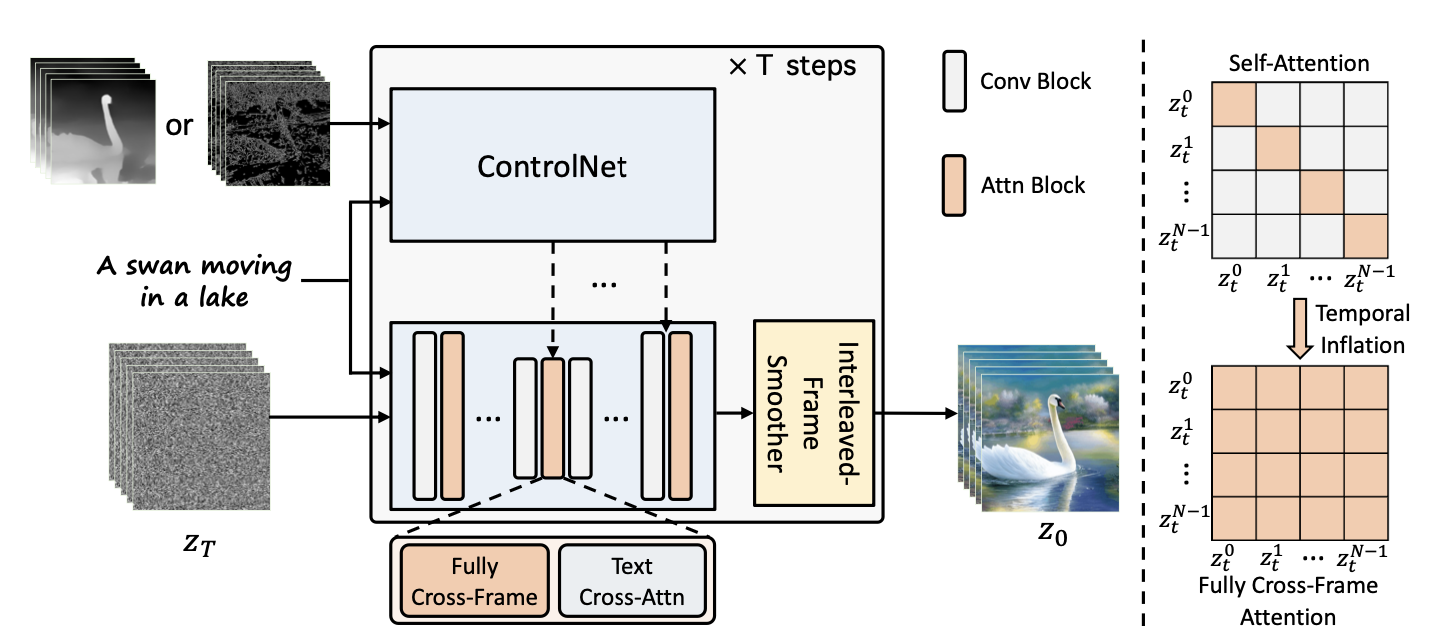
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。ControlVideo の構造概要です。