Gen-1
Gen-1(Esser ら, 2023)は、Runway による video 編集モデルです。Text input に従って既存の video を編集することを目的とし、video の structure と content を分解して条件付け生成を行います。
Structure と content の分離
Gen-1 では、生成の条件付けを次の二つの要素に分解します。
- Content : Video の見た目と semantics を表します。Conditional editing では text から sampling されます。Frame の CLIP embedding は content の良い representation であり、structure の特徴とほぼ orthogonal です。
- Structure : Geometry と dynamics を表します。Object の形状、位置、時間的な変化が含まれます。 は input video から sampling され、depth estimation のような task-specific な side information(人物 video の場合は body pose や face landmark など)が使えます。
ただし、二つの要素を完全に分離するのは容易ではありません。
Architecture
Gen-1 の architecture 変更は標準的なものです。Residual block では、2D spatial convolution の後に 1D temporal convolution を追加し、attention block では、2D spatial attention の後に 1D temporal attention を追加します。
Training では、structure を diffusion latent と concatenate し、content は cross-attention layer 経由で与えます。Inference 時には、prior を使って CLIP text embedding を CLIP image embedding に変換します。
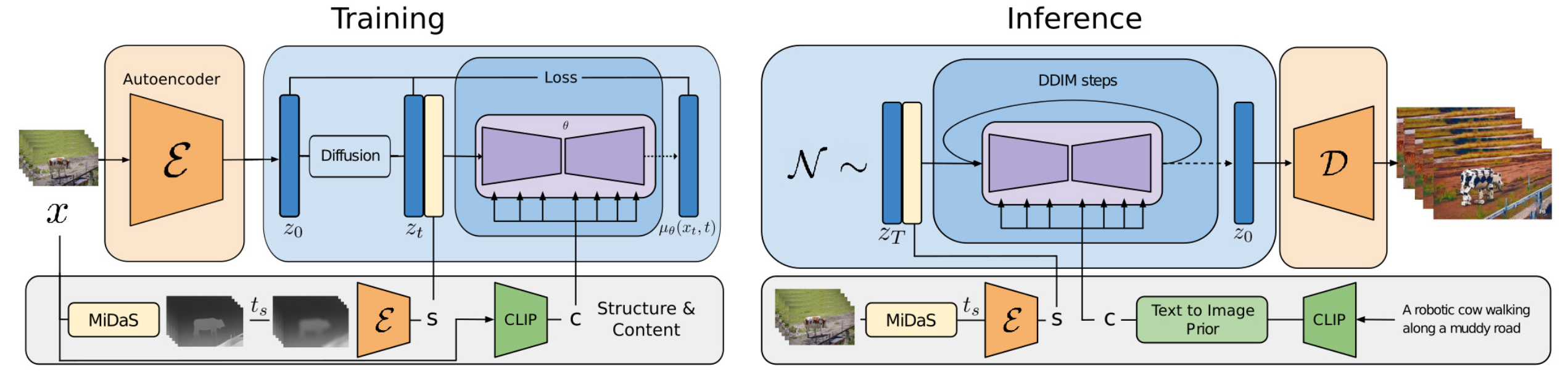
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Gen-1 の training pipeline が示されています。