Imagen Video
Imagen Video(Ho ら, 2022)は、複数の diffusion model を cascade することで、高解像度かつ高品質な video 生成を実現する model です。最終的には の解像度で 24 fps の video を生成できます。
Architecture の構成
Imagen Video は、合計 7 つの diffusion model から構成されています。
- 凍結された T5 text encoder(text embedding を生成して conditioning に使います)
- Base video diffusion model
- 3 つの Temporal Super-Resolution(TSR)model
- 3 つの Spatial Super-Resolution(SSR)model
TSR と SSR は interleaved に配置され、時間方向と空間方向の解像度を交互に上げていきます。
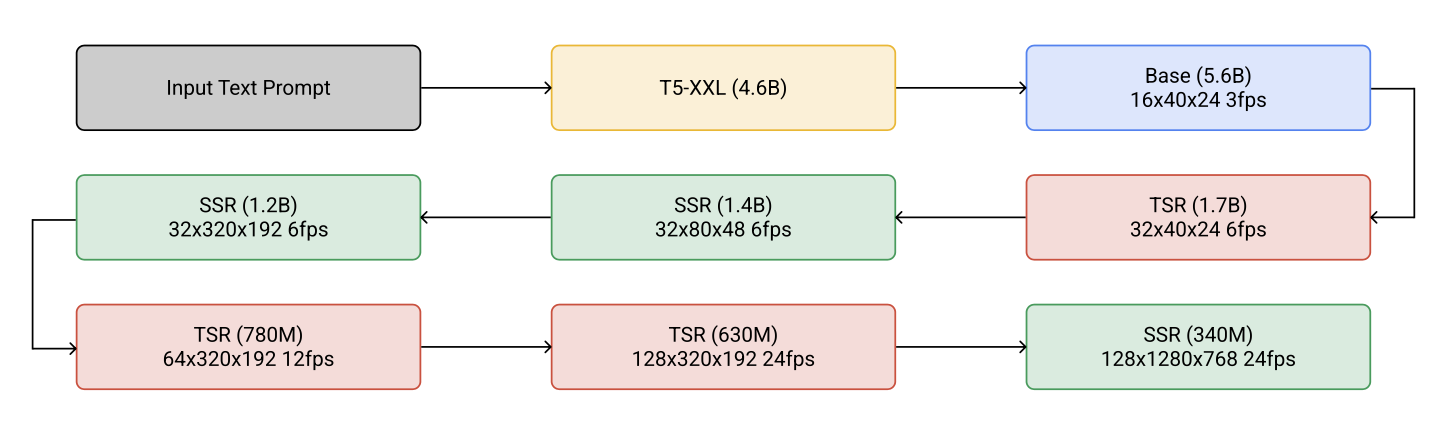
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Imagen Video の cascaded sampling pipeline が示されています。Text embedding は base model だけでなく、すべての component に注入されます。
Base denoising model の構成
Base denoising model では、全 frame に対して shared parameter の spatial operation を同時に適用し、その後に temporal layer によって frame 間の activation を mix します。この「spatial 先・temporal 後」の構成は、frame-autoregressive 方式よりも temporal coherence の点で良い結果を示すと報告されています。
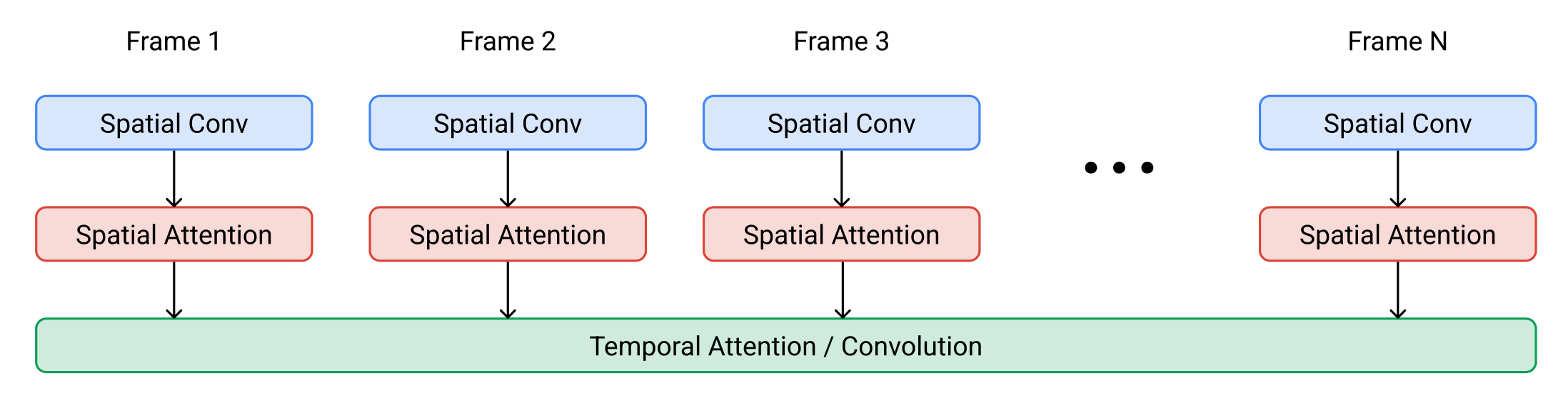
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Imagen Video の space-time separable block の構造です。
Super-resolution の条件づけ
SSR と TSR の model は、どちらも upsample 済みの input を noisy data と channel 方向に concatenate して、条件として受け取ります。Upsample の方法は、SSR では bilinear resizing、TSR では frame の複製または blank frame の挿入です。
Progressive distillation による高速化
Imagen Video では、sampling を高速化するために progressive distillation も適用されています。各蒸留 iteration ごとに必要な sampling step を半分にできます。実験では、7 つの diffusion model のすべてを、知覚品質をほぼ落とさずに、それぞれ 8 step まで蒸留できたと報告されています。