Lumiere
Lumiere(Bar-Tal ら, 2024)は、遠く離れた key frame を先に生成してから temporal super-resolution(TSR)で補間する従来パイプラインを改め、video の全時間長を一度のパスで生成する model です。
なぜ TSR を使わないのか
Imagen Video や Video LDM のように、key frame を疎に生成してから TSR で補間する方式では、長い時間スケールでの temporal consistency を保つことが難しくなります。離れた key frame の間に挟まれる frame は、両端の見え方に強く依存するため、補間の品質が高品質な video 生成のボトルネックになりがちです。
Lumiere はこの問題を回避するために、TSR component を取り除き、Space-Time U-Net(STUNet)を使って video 全体を一度に生成します。
Space-Time U-Net(STUNet)
STUNet は、video を時間方向と空間方向の両方で downsample するため、計算コストの高い処理は compact な time-space latent space の中で行われます。
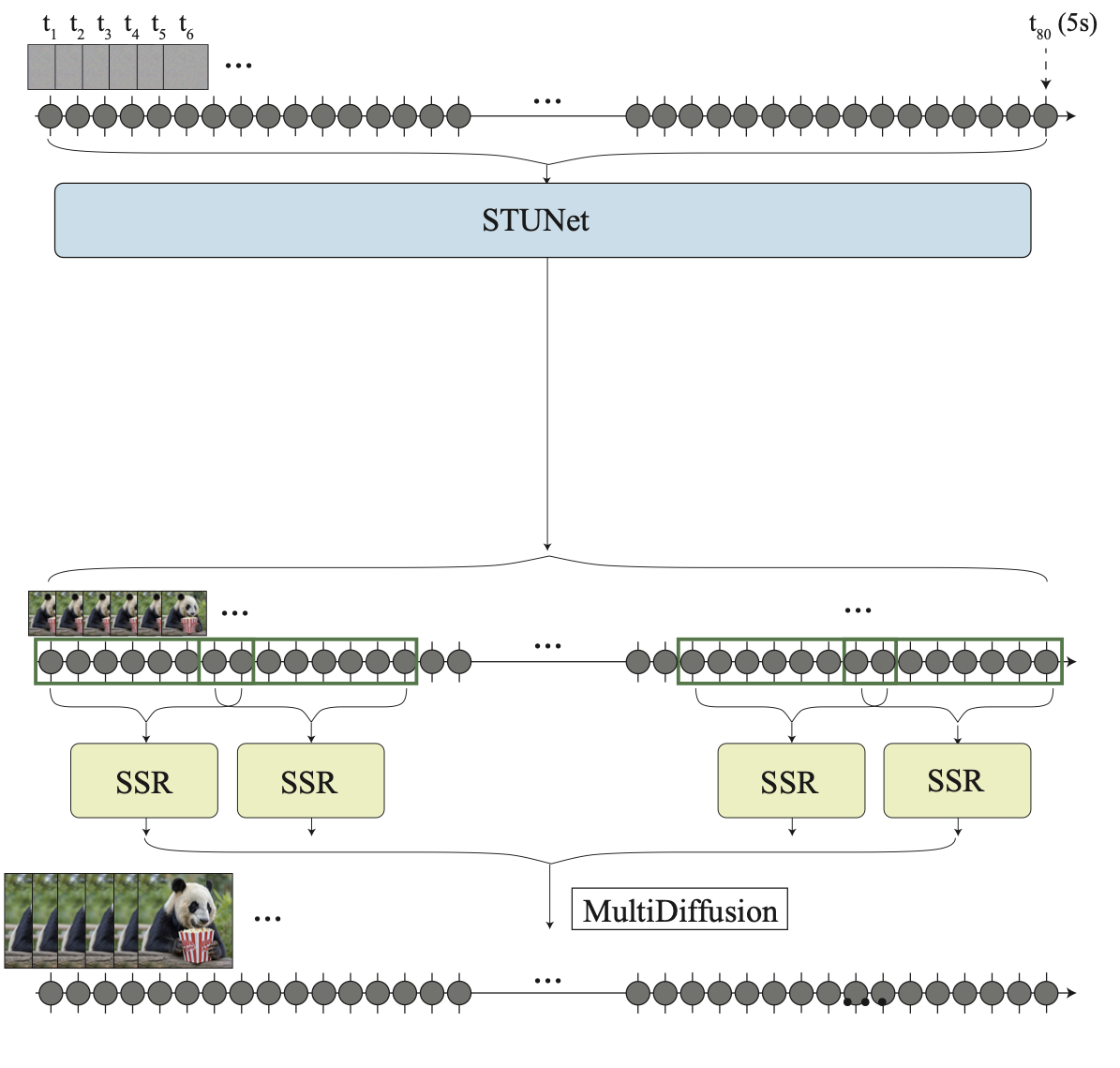
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Lumiere では TSR を取り除いた構成になっています。Inflate された SSR network は memory 制約のため video の短い区間にしか適用できないため、SSR model は重なりを持つ短い video snippet 群に対して動作します。
Architecture の構成
STUNet は、pre-trained な text-to-image U-Net を inflate して、時間方向と空間方向の両方で video を downsample / upsample できるようにします。
- Convolution-based block: Pre-trained text-to-image layer の後に、factorized space-time convolution を続けます。
- Attention-based block: U-Net の最も粗い解像度 level では、pre-trained text-to-image layer の後に temporal attention を続けます。
追加で training されるのは、新しく加えられた layer のみです。
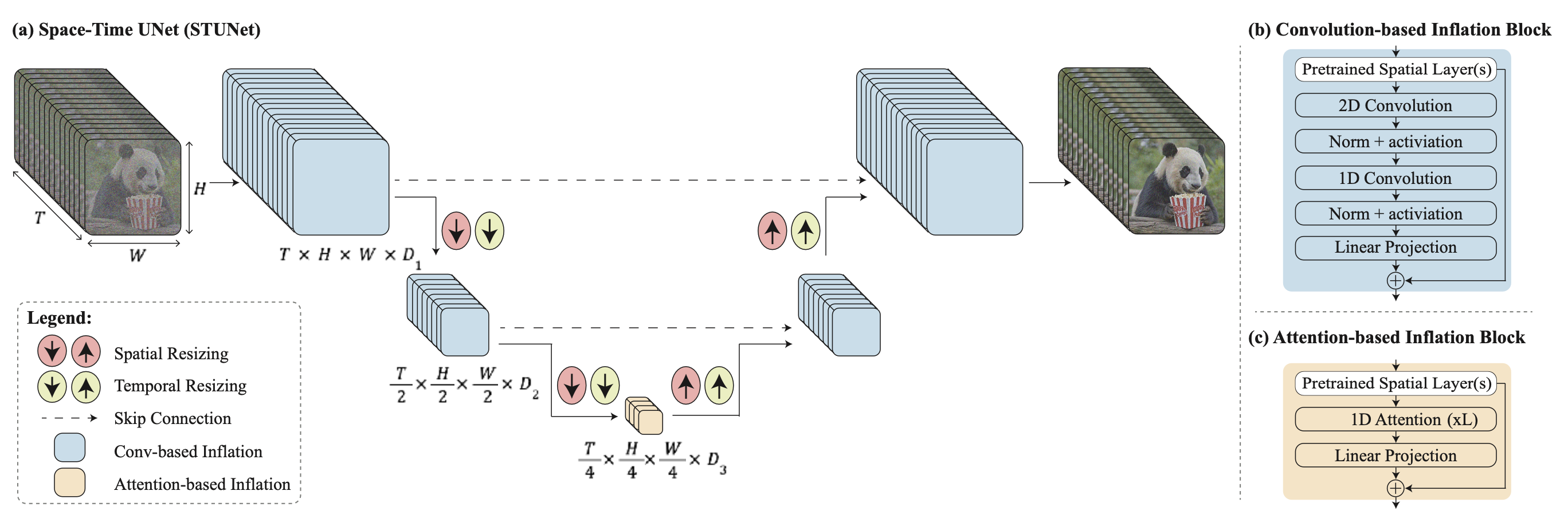
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。(a) Space-Time U-Net(STUNet)、(b) convolution-based block、(c) attention-based block の構造です。
数式で見る Space-Time U-Net
Lumiere のような Space-Time U-Net 系の考え方では、video 全体を一度に扱い、時間方向に分割された短い clip をつなぐのではなく、時空間的に一貫した denoising を行います。
ここで、 は text condition などの条件空間です。この式の気持ちは、「各 frame の noise を別々に予測するのではなく、video tensor 全体の noise をまとめて予測する」ということです。
時間的な一貫性は、隣接 frame の feature が滑らかにつながることとして regularize できます。
ここで、 は feature extractor、 は flow warping です。これは「motion に沿って見たとき、見た目が急に変わらない」ことを促します。