Make-A-Video
Make-A-Video(Singer ら, 2022)は、pre-trained な text-to-image diffusion model に時間方向を加えて、text-to-video model に拡張する代表的な model です。Text-video pair data を必要とせず、text-image pair data と unlabeled video data だけで学習できる点が特徴です。
主要構成
Make-A-Video は、次の三つの component から成り立ちます。
- Text-image pair data で training された base text-to-image model
- 時間方向に network を拡張するための spatiotemporal convolution と attention layer
- 高 frame rate 生成のための frame interpolation network
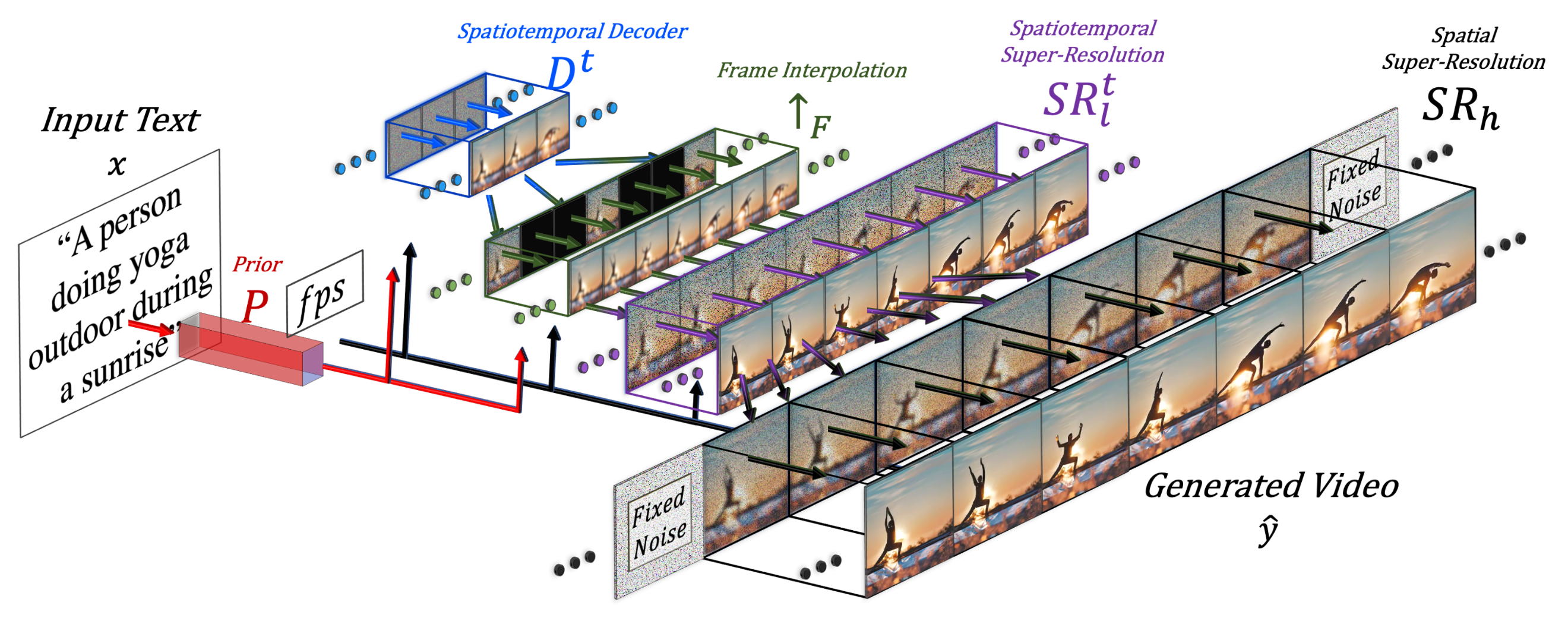
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Make-A-Video の生成パイプラインが示されています。
Pseudo-3D layer
Spatiotemporal super-resolution layer は、pseudo-3D convolution layer と pseudo-3D attention layer から構成されます。
- Pseudo-3D convolution layer: Pre-trained image model から initialize された spatial 2D convolution の後に、identity function として initialize された temporal 1D layer を続ける構造です。
- Pseudo-3D attention layer: Pre-trained な spatial attention layer の後に temporal attention layer を積み重ね、完全な spatiotemporal attention を近似します。
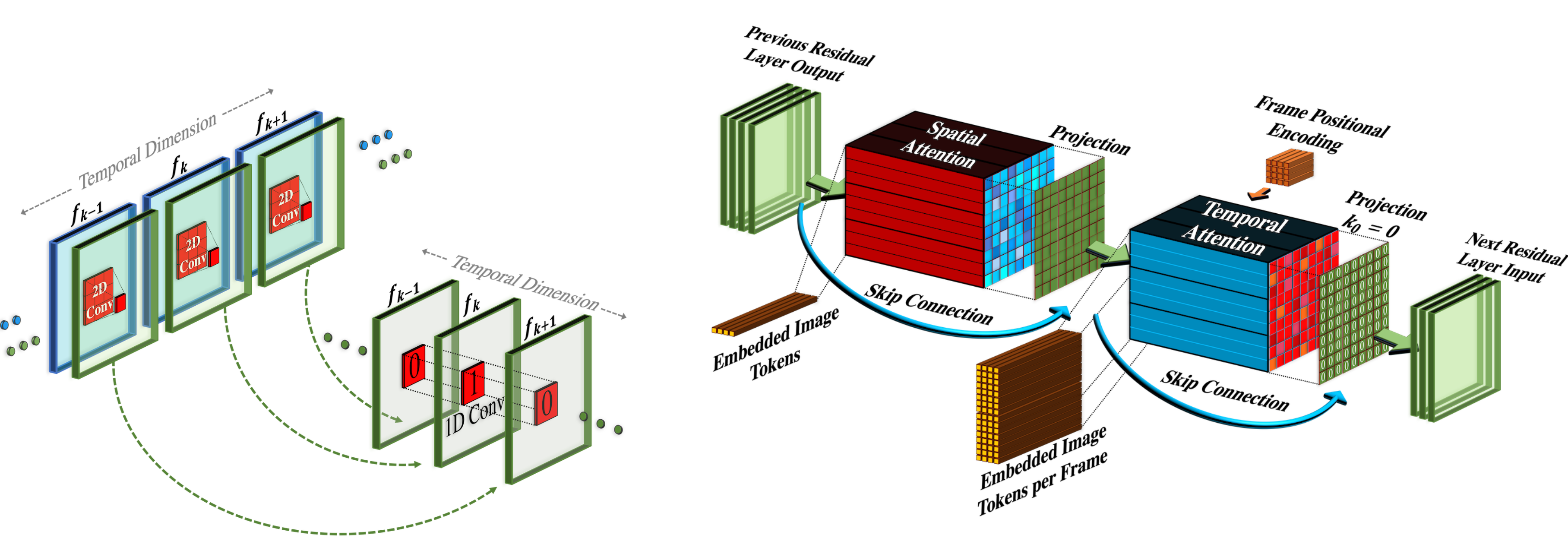
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Pseudo-3D convolution(左)と pseudo-3D attention(右)の構造です。
Input tensor (batch size、channel、frame、height、width)に対して、 は時間軸と空間軸の入れ替えを表します。 は を に変換し、 はその逆変換です。
推論パイプライン
最終的な video 推論は、次のように分解できます。
各 component の意味は次のとおりです。
- は input text、 は BPE encode された text です。
- は CLIP text encoder です。
- は prior であり、text embedding から image embedding を生成します。Text-image pair data で training され、video data では fine-tuning されません。
- は spatiotemporal decoder で、16 frame の低解像度 RGB image を生成します。
- は frame interpolation network で、生成 frame の間を補間して effective frame rate を上げます。
- と はそれぞれ spatial / spatiotemporal super-resolution model です。
- が最終的に生成される video です。
Training 戦略
Make-A-Video は、各 component を独立に training します。
- Decoder 、prior 、二つの super-resolution component を、まず image だけで(pair text なしで)training します。
- 次に、新しい temporal layer を identity function として追加し、unlabeled video data で fine-tuning します。