Parameterization for Video Diffusion
Video Diffusion Models では、denoising model が何を予測するかによって、training の安定性や生成品質が変わります。代表的な parameterization には、ϵ-prediction と v-prediction があります。
Forward process の定義
Real data から sample された x∼qreal に対して、Gaussian noise を時間方向に少しずつ加えた noisy variable の系列を {zt∣t=1,…,T} と書きます。Differentiable な noise schedule (αt,σt) を使うと、forward process は次のように書けます。
q(zt∣x)=N(zt;αtx,σt2I)
0≤s<t≤T に対しては、log signal-to-noise ratio λt=log[αt2/σt2] を使うと、DDIM の更新式は次のように書けます。
q(zt∣zs)=N(zt;αsαtzs,σt∣s2I),σt∣s2=(1−eλt−λs)σt2
v-parameterization
Salimans と Ho(2022)によって提案された v-prediction は、次のように定義されます。
v=αtϵ−σtx
Angular coordinate を使うと、この parameterization の意味が見えやすくなります。ϕt=arctan(σt/αt) と置くと、αt=cosϕ、σt=sinϕ、zϕ=cosϕx+sinϕϵ と書けます。このとき、zϕ の velocity は
vϕ=∇ϕzϕ=cosϕϵ−sinϕx
となり、DDIM の更新式は三角関数を使った compact な形
zϕs=cos(ϕs−ϕt)zϕt+sin(ϕs−ϕt)v^θ(zϕt)
に書き直せます。直感的には、DDIM の更新は angular coordinate における −v^ϕt 方向への移動として理解できます。
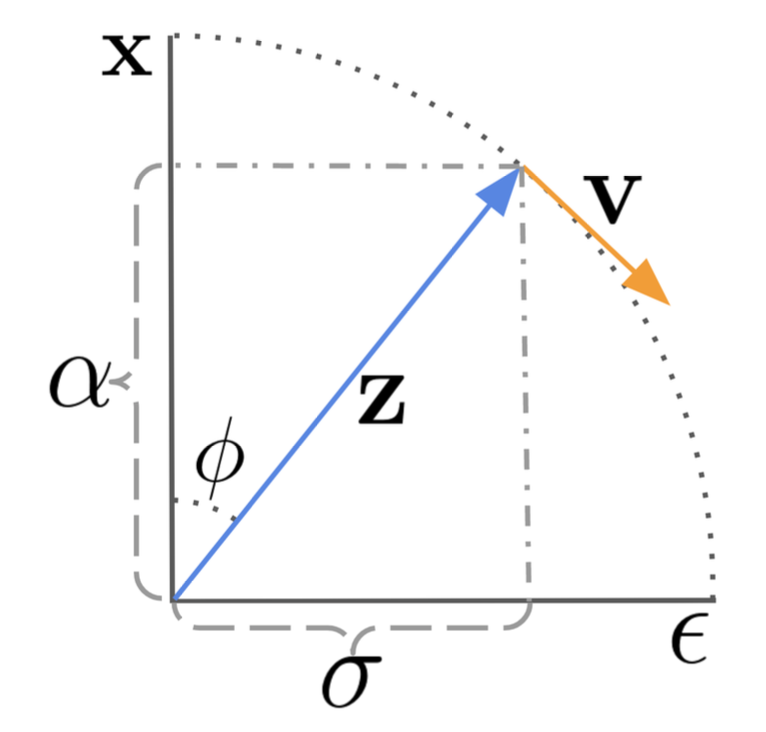
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Angular coordinate 上で DDIM が −v^ϕt 方向に zϕs を更新する様子が示されています。
なぜ video で v-prediction が好まれるのか
ϵ-prediction と比べて、v-prediction は video generation における color shift を抑える効果があると報告されています。Frame 間で色味が時間的にずれてしまう問題は video 特有の artifact になりやすいため、v-prediction が広く使われます。
関連ページ