Text2Video-Zero(Khachatryan ら, 2023)は、追加の training をまったく行わずに、pre-trained な text-to-image diffusion model を使って video を生成する training-free な手法です。
Latent code を単純にランダムに sample してそれぞれ画像に decode しただけでは、生成された frame 列に object や semantics の時間的整合性は保証されません。Text2Video-Zero は、この問題を二つの仕組みで解決します。
- Latent code の sequence に motion dynamics を持たせることで、global な scene と背景の時間的整合性を保ちます。
- Frame ごとの self-attention を、最初の frame に対する cross-frame attention に書き換え、前景 object の見た目や identity を保ちます。
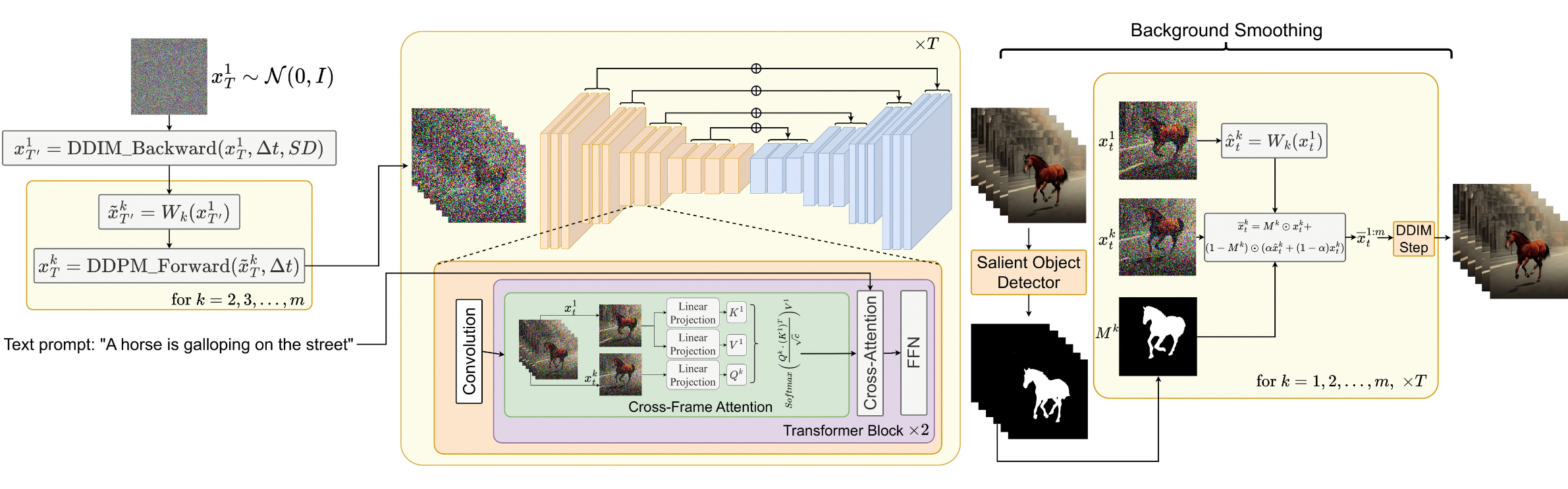
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Text2Video-Zero のパイプライン概要です。
Motion を持たせた latent 系列の生成
Motion 付きの latent variable 系列 xT1,…,xTm は、次の手順で生成されます。
- Global な scene と camera motion を制御する方向 δ=(δx,δy)∈R2 を定義します。既定では δ=(1,1) です。Motion の量を制御する hyperparameter λ>0 も定義します。
- 最初の frame の latent code を xT1∼N(0,I) として sample します。
- Pre-trained な image diffusion model(論文では Stable Diffusion)を使って、Δt≥0 step の DDIM backward update を行い、T′=T−Δt における latent code xT′1 を得ます。
- 各 frame について、δk=λ(k−1)δ で定義される warping 操作を適用し、x~T′k を得ます。
- 最後に、x~T′2:m に DDIM forward step を適用し、xT2:m を得ます。
xT′1Wkx~T′kxTk=DDIM-backward(xT1,Δt),T′=T−Δt←warping operation of δk=λ(k−1)δ=Wk(xT′1)=DDIM-forward(x~T′k,Δt)for k=2,…,m
Cross-frame attention
Text2Video-Zero では、pre-trained Stable Diffusion の self-attention layer を、最初の frame を参照する cross-frame attention に置き換えます。これによって、前景 object の見た目、形状、identity を全体の video を通して保つことを狙います。
Cross-Frame-Attn(Qk,K1:m,V1:m)=Softmax(cQk(K1)⊤)V1
Background smoothing
Optional な仕組みとして、background mask を使って背景の整合性をさらに高めることもできます。k 番目の frame に対する前景 mask Mk を別途求めておき、diffusion step t において actual latent code と warped latent code を mask に従って混ぜます。
xˉtk=Mk⊙xtk+(1−Mk)⊙(αx~tk+(1−α)xtk),k=1,…,m
ここで、xtk は actual latent、x~tk は背景に対する warped latent です。論文の実験では α=0.6 が使われています。
ControlNet との併用
Text2Video-Zero は ControlNet と組み合わせることもできます。各 diffusion time step t=T,…,1 において、各 frame xtk(k=1,…,m)に対して ControlNet の pretrained copy branch を適用し、その出力を main U-Net の skip connection に加えます。
関連ページ