Tune-A-Video
Tune-A-Video(Wu ら, 2023)は、pre-trained な image diffusion model を inflate して、1 本の video からの one-shot fine-tuning で text-to-video の編集を行う model です。
目的
個の frame からなる video と、その内容を記述する prompt が与えられたとき、少し編集した別の prompt に基づいて新しい video を生成する task を扱います。たとえば、 "A man is skiing" を "Spiderman is skiing on the beach" のように書き換えて生成します。
Tune-A-Video は、object editing、background change、style transfer などの編集用途を想定しています。
ST-Attention
Tune-A-Video の U-Net では、2D convolution layer を inflate するだけでなく、temporal consistency を保つために ST-Attention(spatiotemporal attention)block を導入します。Frame の latent feature を query にし、最初の frame と直前の frame を key と value にすることで、関連する位置への参照を行います。
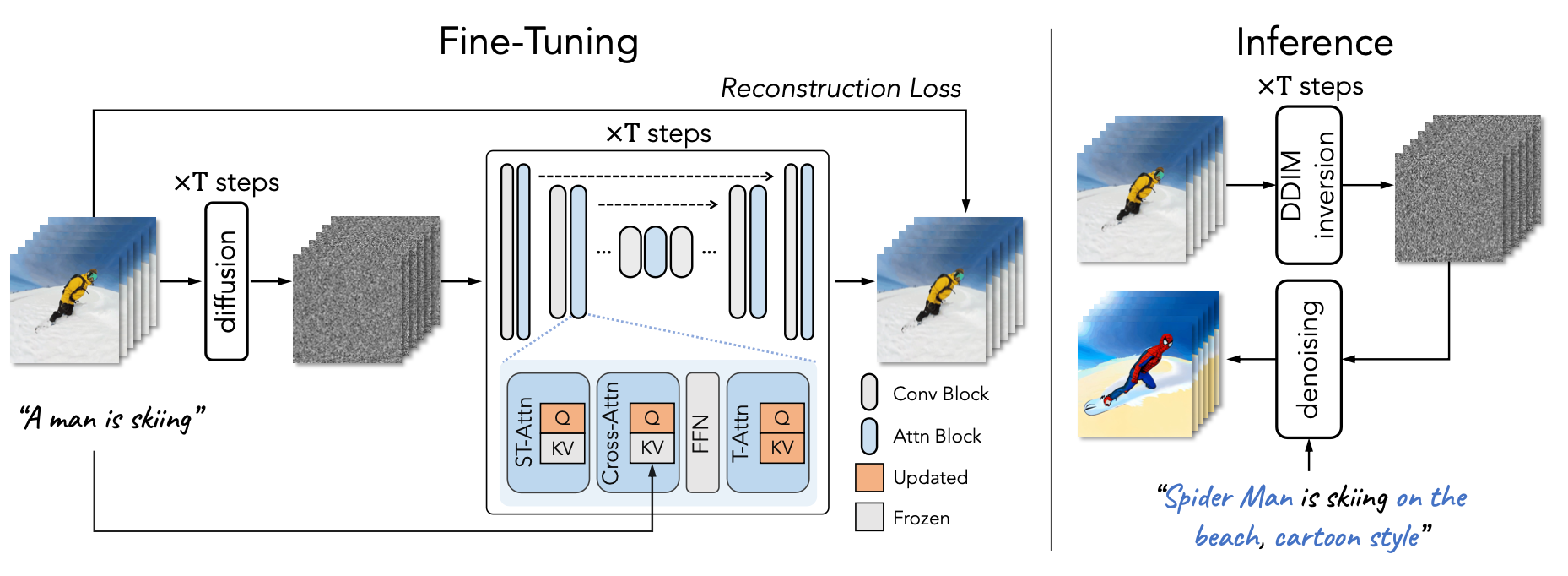
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Tune-A-Video は、sampling の前に 1 本の video で軽量な fine-tuning を行います。新しく追加された temporal self-attention(T-Attn)layer は全体が fine-tuning される一方で、ST-Attn と Cross-Attn では query projection のみが更新され、text-to-image の事前知識を保ちます。ST-Attn は spatio-temporal consistency を高め、Cross-Attn は text-video alignment を補正します。
何を fine-tuning するか
Tune-A-Video の fine-tuning では、何を更新するかを慎重に選びます。
- 新しく追加された temporal self-attention layer は全体を更新します。
- ST-Attn と Cross-Attn では query projection のみを更新し、text-to-image の事前知識を維持します。
これによって、軽量な fine-tuning で video editing 能力を獲得できます。