Video LDM and Stable Video Diffusion
Video LDM(Blattmann ら, 2023)と Stable Video Diffusion(SVD; Blattmann ら, 2023)は、Latent Diffusion Model(LDM)を video へ拡張した model 群です。Pre-trained な image LDM を活かしつつ、temporal layer を追加することで動画生成を実現します。
Video LDM
Video LDM では、まず image LDM を training し、その後に temporal dimension を加えて video を生成するように fine-tuning します。Fine-tuning の対象は、新しく追加された temporal layer のみであり、既存の spatial layer は凍結されます。
Video LDM のパイプラインは、まず低 fps で key frame を生成し、その後に 2 段階の latent frame interpolation で fps を上げる構成です。
Input sequence の長さ は、image backbone に対しては batch()として渡され、temporal layer に対しては video 形状に reshape されます。Skip connection によって、temporal layer 出力 と spatial 出力 は学習可能な merging parameter で結合されます。実装される temporal mixing layer には、(1) temporal attention と、(2) 3D convolution に基づく residual block の二種類があります。
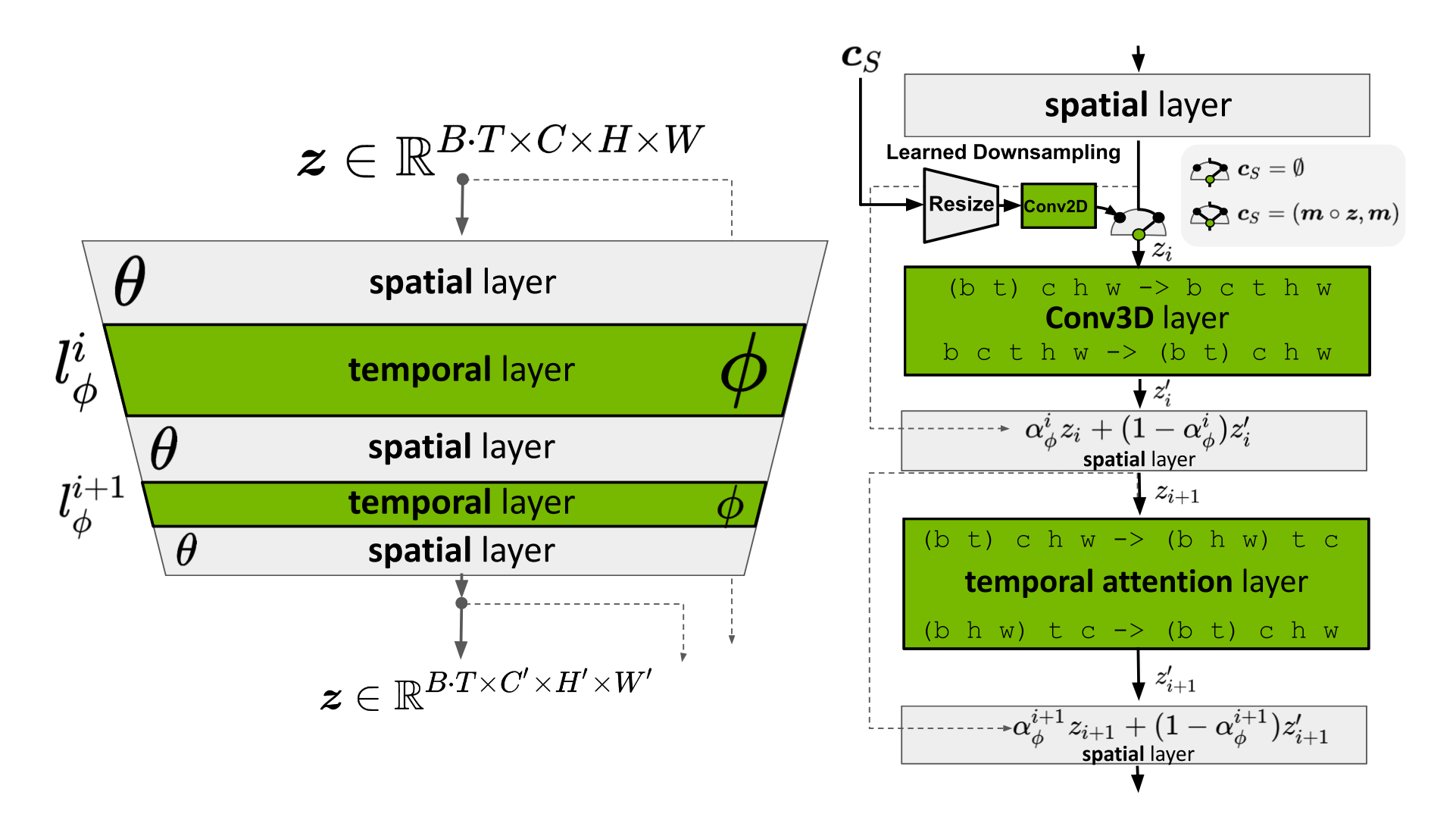
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Image LDM が video generator に拡張される構造です。 はそれぞれ batch size、sequence length、channel、height、width を表します。 は optional な conditioning / context frame です。
Temporal autoencoder
LDM の pre-trained autoencoder は image のみで training されているため、それをそのまま video に使うと、flickering artifact が出やすく、temporal coherence が損なわれます。Video LDM ではこの問題に対処するために、decoder 側に temporal layer を追加し、3D convolution による patch-wise temporal discriminator を使って video data で fine-tuning します。Encoder は変更せず、pre-trained LDM をそのまま再利用できるようにします。
Temporal decoder の fine-tuning では、凍結された encoder が各 frame を独立に処理し、video-aware discriminator が frame 間で時間的に整合する reconstruction を促します。
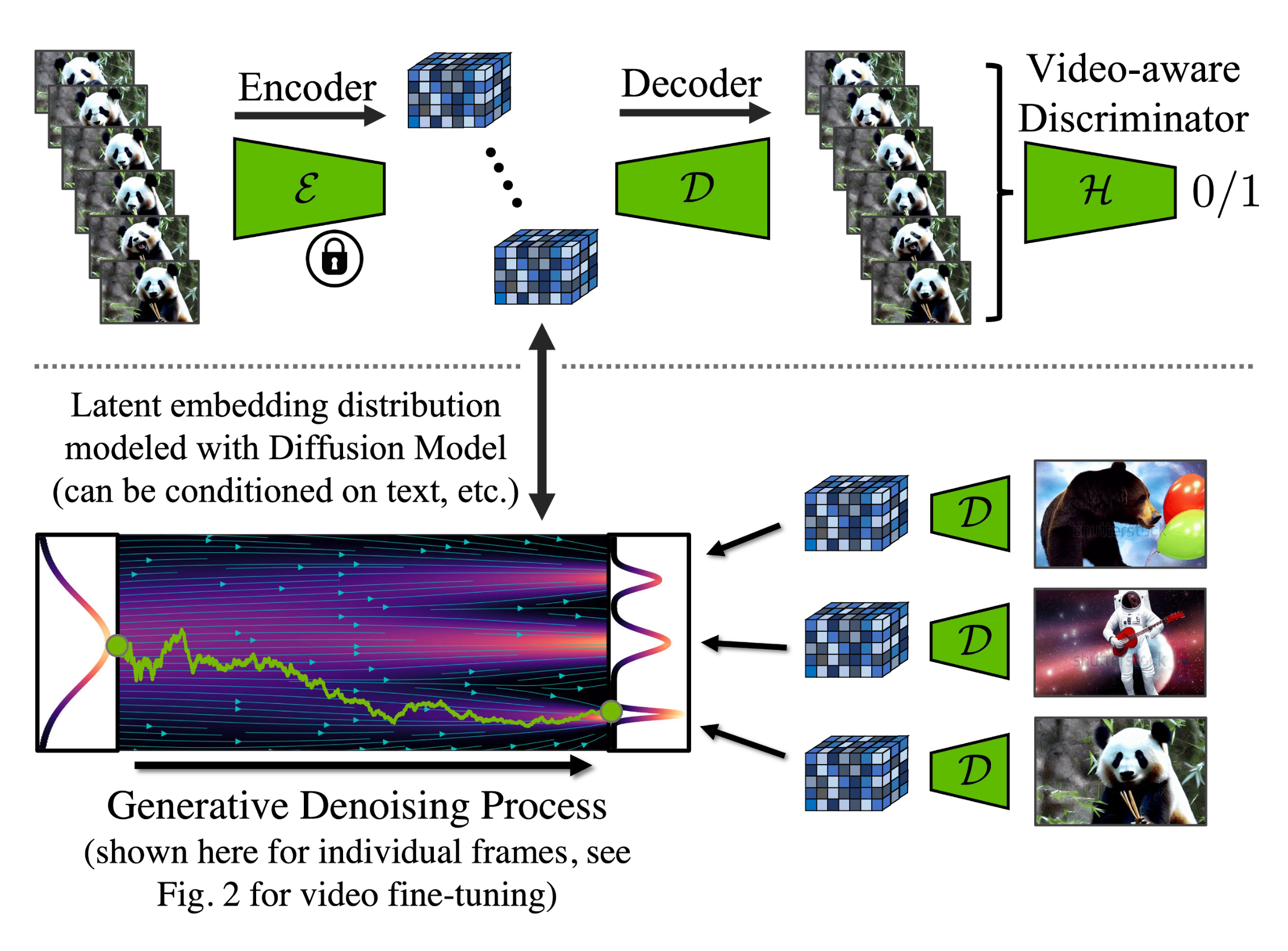
画像出典: Lilian Weng, “Diffusion Models for Video Generation”。Video latent diffusion における autoencoder の training pipeline です。Encoder は凍結し、decoder のみが across-frame discriminator とともに fine-tuning されます。
Stable Video Diffusion
Stable Video Diffusion(SVD)も Video LDM と同様に、各 spatial convolution と attention layer の後に temporal layer を挿入する構成です。ただし、SVD では model 全体が fine-tuning されます。
SVD では、video LDM の training を次の三段階に分けています。
- Text-to-image pretraining: 品質と prompt 追従性の両方を改善するために重要です。
- Video pretraining: 大規模で curate された dataset を使って、独立した段階として行うのが望ましいとされています。
- High-quality video finetuning: 比較的小さいが、事前 caption 付きの高品質 video で fine-tuning します。
Dataset curation の重要性
SVD では、dataset curation が model 性能に与える影響が特に強調されています。具体的には、次のような pipeline が使われます。
- Cut detection pipeline によって、各 video からより多くの cut を抽出します。
- 三つの captioner model を組み合わせて caption を生成します。
- CoCa による mid-frame caption
- V-BLIP による video caption
- LLM ベースの captioning(上記二つの caption をもとに生成)
- 動きが少ない clip(2 fps で計算した optical flow score が低いもの)を除外します。
- Text が過剰に映る clip(OCR で検出)を除外します。
- 美的価値が低い clip を除外します。各 clip の最初、中央、最後の frame に CLIP embedding を付与し、美的 score と text-image 類似度を計算します。
実験では、たとえ dataset が大幅に小さくなっても、filtering された高品質 dataset の方が良い model 品質につながると報告されています。