Wasserstein Distance は、二つの probability distribution の距離を測る指標です。直感的には、ある distribution の形をした土の山を、別の distribution の形へ変形するために必要な最小のコストとして理解できます。
このため、Wasserstein Distance は Earth Mover's Distance(EM Distance)とも呼ばれます。
Earth Mover's Distance の直感
Earth Mover's Distance では、コストは「動かした土の量」と「動かした距離」の積として考えます。
cost=moved amount×moving distance
たとえば、discrete な domain に四つの位置があり、二つの distribution P と Q が同じ総量の土を持っているとします。
P1=3, P2=2, P3=1, P4=4Q1=1, Q2=2, Q3=4, Q4=3
P を Q と同じ形に変えるには、余っている場所から足りない場所へ土を移動します。
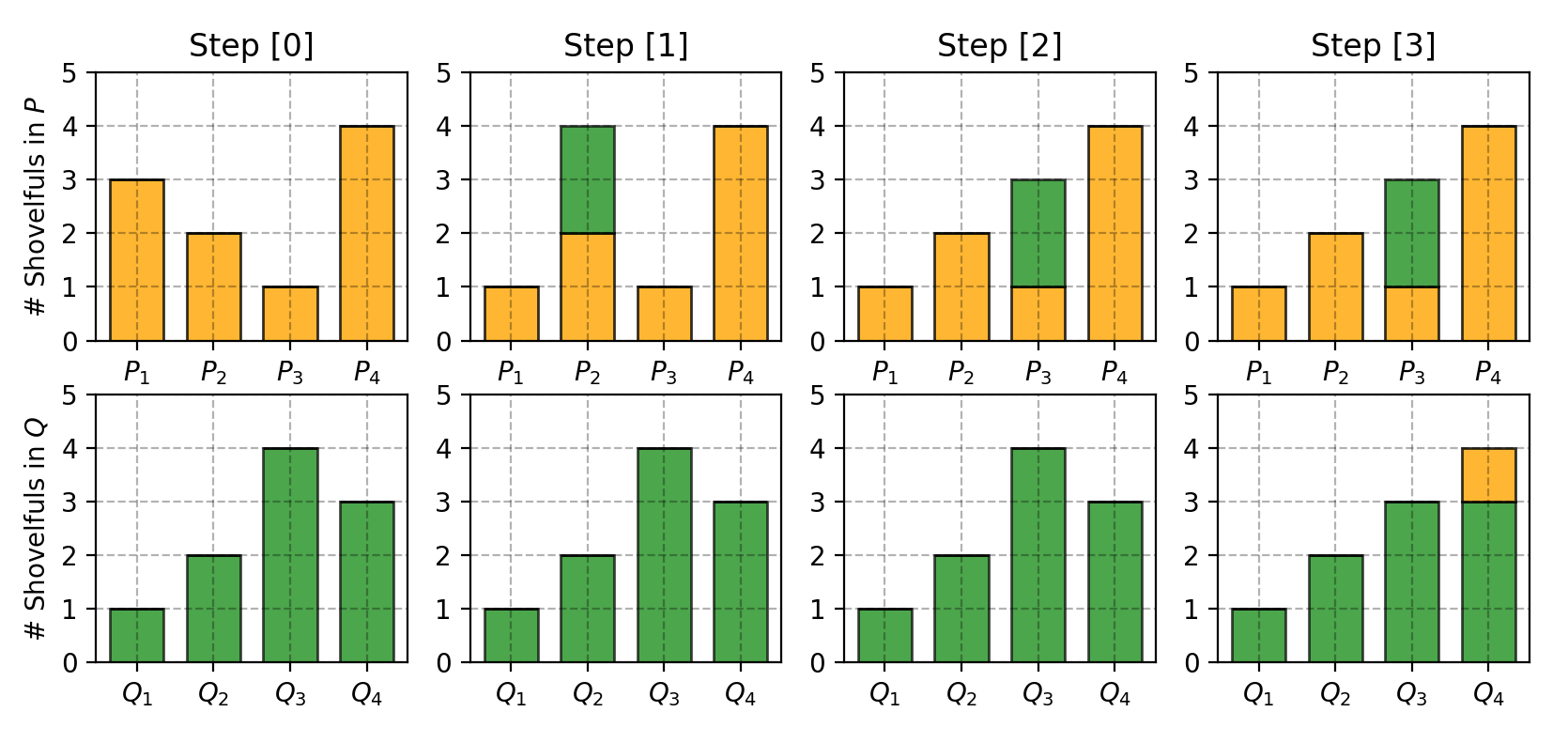
画像出典: Lilian Weng, “From GAN to WGAN”。P の土の山を Q に一致させるために、どのように土を移動するかが示されています。
Pi と Qi を一致させるために必要な差分を δi と書き、δi+1=δi+Pi−Qi とすると、この例では次のようになります。
δ0δ1δ2δ3δ4=0=0+3−1=2=2+2−2=2=2+1−4=−1=−1+4−3=0
したがって、Earth Mover's Distance は次のように計算できます。
W=i∑∣δi∣=5
Continuous distribution での定義
Continuous な probability distribution の場合、Wasserstein Distance は次のように定義されます。
W(pr,pg)=γ∼Π(pr,pg)infE(x,y)∼γ[∥x−y∥]
ここで、Π(pr,pg) は、pr と pg の間で考えられるすべての joint probability distribution の集合です。一つの γ∈Π(pr,pg) は、点 x から点 y へどれだけの土を運ぶかを表す transport plan として解釈できます。
inf は infimum、つまり下限を意味します。したがって、この定義は、すべての transport plan の中で期待コストが最小になるものを選ぶことを意味します。
KL Divergence や JS Divergence との違い
Wasserstein Distance の大きな利点は、二つの distribution の support が重なっていない場合でも、距離を意味のある滑らかな値として表せることです。
単純な例として、二つの distribution P と Q を考えます。
∀(x,y)∈P, x=0 and y∼U(0,1)
∀(x,y)∈Q, x=θ, 0≤θ≤1 and y∼U(0,1)
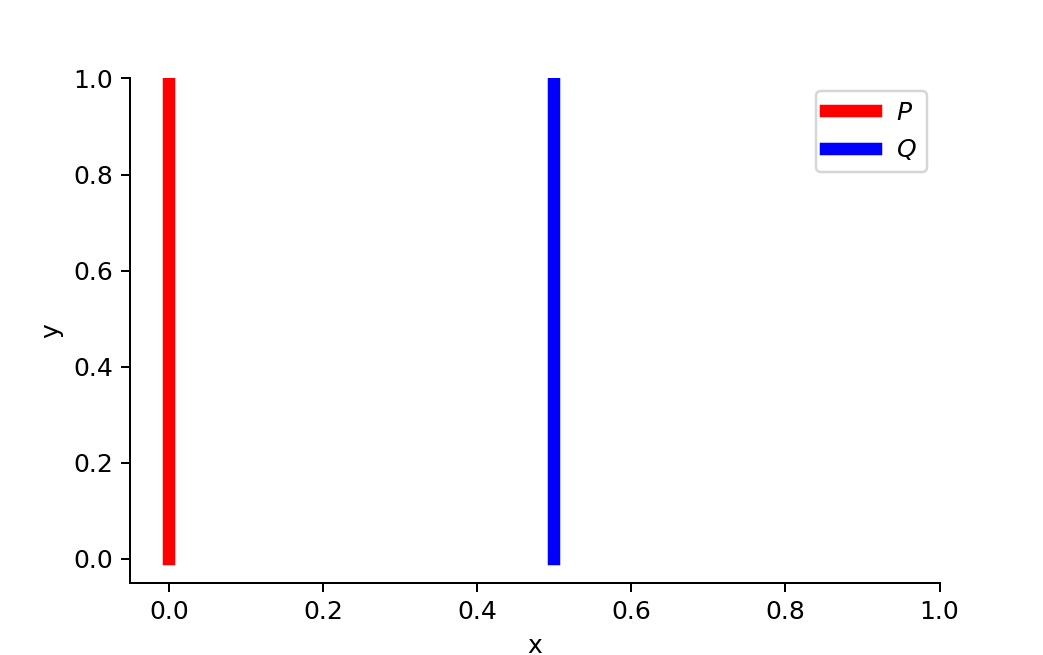
画像出典: Lilian Weng, “From GAN to WGAN”。θ=0 のとき、P と Q は overlap しません。
θ=0 のとき、P と Q は disjoint になります。この場合、各距離は次のようになります。
DKL(P∥Q)DKL(Q∥P)DJS(P,Q)W(P,Q)=+∞=+∞=log2=∣θ∣
一方で、θ=0 のときには、二つの distribution は完全に overlap します。
DKL(P∥Q)=DKL(Q∥P)=DJS(P,Q)=0
W(P,Q)=0=∣θ∣
KL Divergence は、二つの distribution が disjoint であるときに無限大になります。Jensen-Shannon Divergence は、θ=0 の点で急に値が変わり、滑らかではありません。一方で、Wasserstein Distance は ∣θ∣ のように滑らかに変化します。
この滑らかさは、gradient descent による training にとって非常に重要です。
GAN で重要になる理由
GAN では、real data distribution pr と generated distribution pg の support が、高次元空間の中で重なりにくいことがあります。この状況では、JS Divergence に基づく training signal が不安定になりやすくなります。
Wasserstein Distance は、support が disjoint であっても distance を滑らかに与えるため、Wasserstein GAN の loss として使われます。
関連ページ