KL Divergence
KL Divergence、つまり Kullback-Leibler Divergence は、ある probability distribution が、基準となる別の probability distribution からどれくらい離れているかを測る divergence です。
連続変数の場合、KL Divergence は次のように定義されます。
と がすべての で一致しているとき、 は最小値である になります。
直感
KL Divergence は、「 を使って を説明しようとしたときに、どれくらい余分な情報量が必要になるか」と捉えることができます。したがって、 を基準にして を評価する指標です。
この「どちらを基準にするか」が、KL Divergence を理解するうえで非常に重要です。
非対称性
KL Divergence は一般に symmetric ではありません。つまり、次の二つは同じ値になるとは限りません。
特に、 がほぼ で が十分に大きい場合、 では、その差はあまり強く反映されません。一方で、 が大きいにもかかわらず が に近い場合には、値が非常に大きくなります。
この性質は、二つの distribution を対等に比較したいときには扱いにくい場合があります。
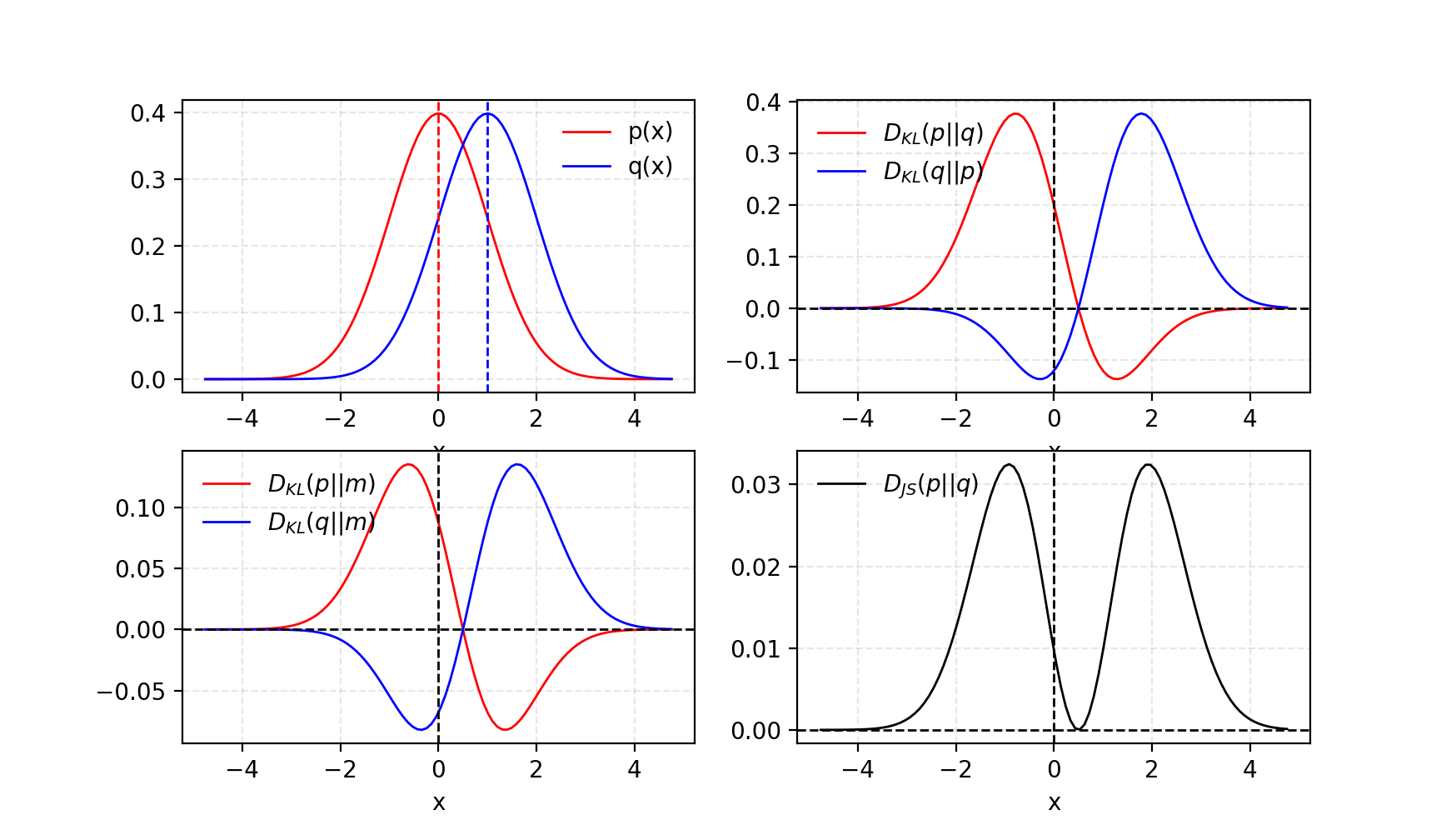
画像出典: Lilian Weng, “From GAN to WGAN”。二つの Gaussian distribution と、その平均 distribution を使って、KL Divergence の非対称性と JS Divergence の対称性を示しています。
GAN との関係
伝統的な maximum likelihood の発想では、KL Divergence に近い objective が現れやすくなります。一方で、vanilla GAN の objective は、optimal Discriminator を仮定すると Jensen-Shannon Divergence と深く関係します。
そのため、GAN の成功の一因として、asymmetric な KL Divergence 的な目的から、symmetric な Jensen-Shannon Divergence 的な目的へ移ったことを挙げる見方があります。
ただし、Jensen-Shannon Divergence にも弱点があり、real distribution と generated distribution の support がほとんど重ならない場合には、Generator にとって有用な gradient を与えにくくなります。この問題をさらに避けるために、Wasserstein GAN では Wasserstein Distance が使われます。